Eval-Driven Design with NextJS and mdx-prompt
In the previous article, we went on a deep dive into how I use mdx-prompt on bragdoc.ai to write clean, composable LLM prompts using good old JSX. In that article as well as the mdx-prompt announcement article, I promised to talk about Evals and their role in helping you architect and build AI apps that you can actually prove work.
Evals are to LLMs what unit tests are to deterministic code. They are an automated measure of the degree to which your code functions correctly. Unit tests are generally pretty easy to reason about, but LLMs are usually deployed to do non-deterministic and somewhat fuzzy things. How do we test functionality like that?
In the last article we looked at the extract-achievements.ts file from bragdoc.ai, which is responsible for extracting structured work achievement data using well-crafted LLM prompts. Here's a reminder of what that Achievement extract process looks like, with its functions to fetch, render and execute the LLM prompts.
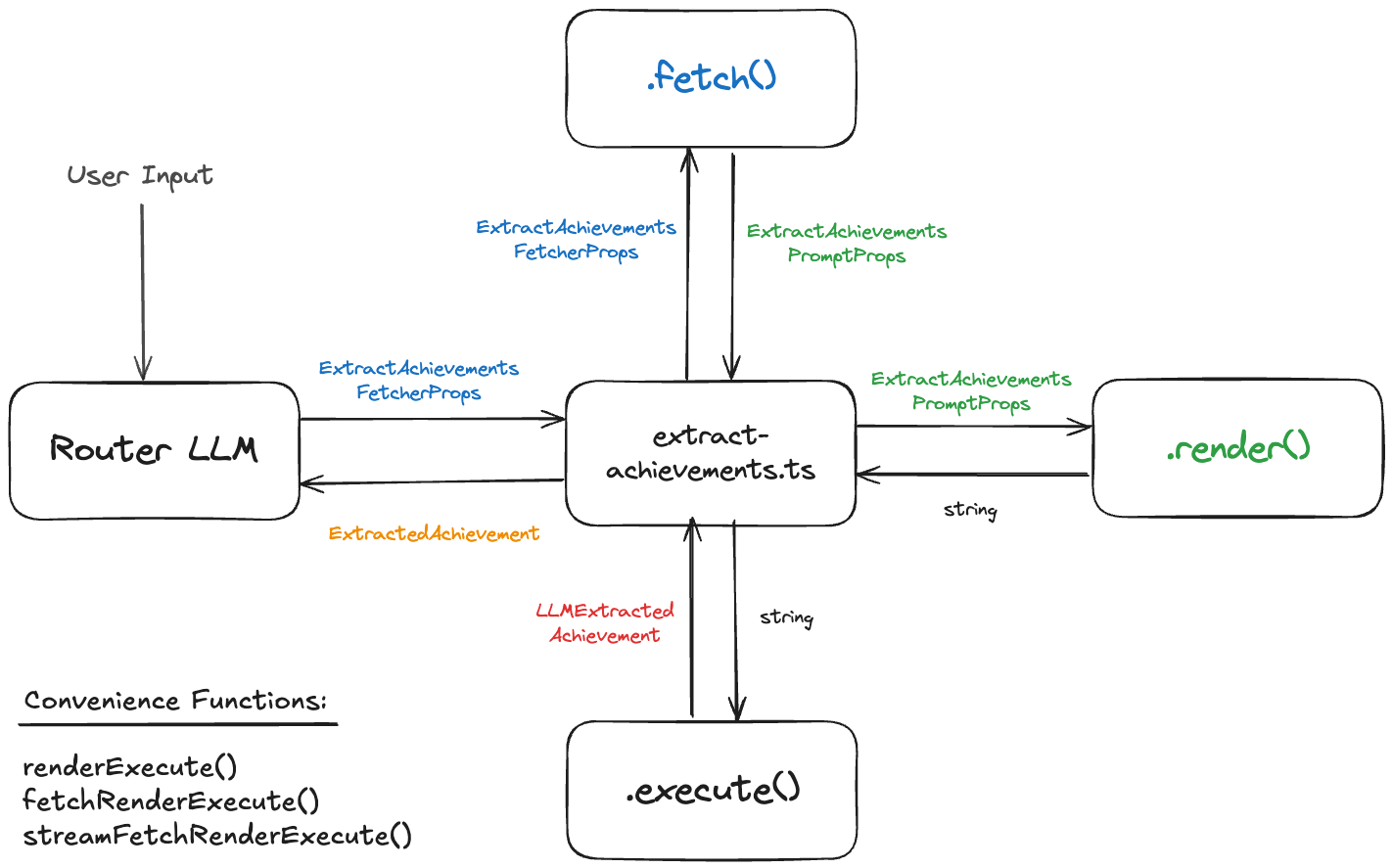
When it comes right down to it, when we say we want to test this LLM integration, what we're trying to test is render() plus execute(), or our convenience function renderExecute. This allows us to craft our own ExtractAchievementsPromptProps and validate that we get reasonable-looking ExtractedAchievement objects back.
ExtractAchievementsPromptProps is just a TS interface that describes all the data we need to render the LLM prompt to extract achievements from a chat session. It looks like this:
mdx-prompt: Real World Example Deep Dive
I just released mdx-prompt, which is a simple library that lets you write familiar React JSX to render high quality prompts for LLMs. Read the introductory article for more general info if you didn't already, but the gist is that we can write LLM Prompts with JSX/MDX like this:
This ought to look familiar to anyone who's ever seen React code. This project was born of a combination of admiration for the way IndyDevDan and others structure their LLM prompts, and frustration with the string interpolation approaches that everyone takes to generating prompts for LLMs.
In the introductory post I go into some details on why string interpolation-heavy functions are not great for prompts. It's a totally natural thing to want to do - once you've started programming against LLM interfaces, you want to start formalizing the mechanism by which you generate the string that is the prompt. Before long you notice that many of your app's prompts have a lot of overlap, and you start to think about how you can reuse the parts that are the same.
Lots of AI-related libraries try to help you here with templating solutions, but they often feel clunky. I really, really wanted to like Langchain, but I lost a day of my life trying to get it to render a prompt that I could have done in 5 minutes with JSX. JSX seems to be a pretty good fit for this problem, and anyone who knows React (a lot of people) can pick it up straight away. mdx-prompt helps React developers compose their LLM prompts with the familiar syntax od JSX.
Anyway, let's get on with it - we're meant to be talking about Evals.
The Setup
mdx-prompt: Composable LLM Prompts with JSX
I'm a big fan of IndyDevDan's YouTube channel. He has greatly expanded my thinking when it comes to LLMs. One of the interesting things he does is write many of his prompts with an XML structure, like this:
I really like this structure. Prompt Engineering has been a dark art for a long time. We're suddenly programming using English, which is hilariously imprecise as a programming language, and it feels not quite like "real engineering".
But prompting is actually not programming in English, it's programming in tokens. It just looks like English, so it's easy to fall into the trap of giving it English. But we're not constrained to that at all actually - we can absolutely format our prompts more like XML and reap some considerable rewards:
- It's easier for humans to reason about prompts in this format
- It's easier to reuse content across prompts
- It's easier to have an LLM generate a prompt in this format (see IndyDevDan's metaprompt video)
We've seen this before
I've started migrating many of my prompts to this format, and noticed a few things:
- It organized my thinking around what data the prompt needs
- Many prompts could or should use the same data, but repeat fetching/rendering logic each time