I just released mdx-prompt, which is a simple library that lets you write familiar React JSX to render high quality prompts for LLMs. Read the introductory article for more general info if you didn't already, but the gist is that we can write LLM Prompts with JSX/MDX like this:
extract-commit-achievements.mdx
<Prompt>
<Purpose>
You are a careful and attentive assistant who extracts work achievements
from source control commit messages. Extract all of the achievements in
the commit messages contained within the <user-input> tag. Follow
all of the instructions provided below.
</Purpose>
<Instructions>
<Instruction>Each Achievement should be complete and self-contained.</Instruction>
<Instruction>If multiple related commits form a single logical achievement, combine them.</Instruction>
This ought to look familiar to anyone who's ever seen React code. This project was born of a combination of admiration for the way IndyDevDan and others structure their LLM prompts, and frustration with the string interpolation approaches that everyone takes to generating prompts for LLMs.
In the introductory post I go into some details on why string interpolation-heavy functions are not great for prompts. It's a totally natural thing to want to do - once you've started programming against LLM interfaces, you want to start formalizing the mechanism by which you generate the string that is the prompt. Before long you notice that many of your app's prompts have a lot of overlap, and you start to think about how you can reuse the parts that are the same.
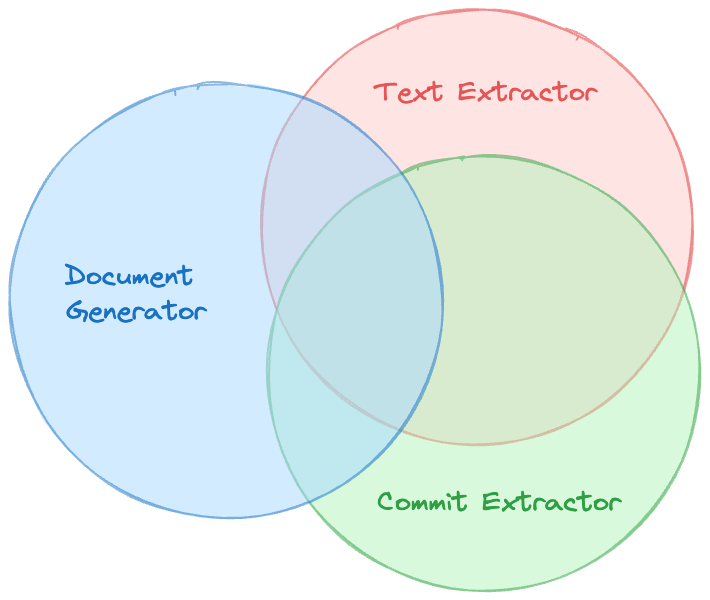
The Venn Diagram of these 3 prompts used in bragdoc.ai shows a large degree of overlap
Lots of AI-related libraries try to help you here with templating solutions, but they often feel clunky. I really, really wanted to like Langchain, but I lost a day of my life trying to get it to render a prompt that I could have done in 5 minutes with JSX. JSX seems to be a pretty good fit for this problem, and anyone who knows React (a lot of people) can pick it up straight away. mdx-prompt helps React developers compose their LLM prompts with the familiar syntax od JSX.
The Setup
In this article we'll take a deeper look at this actual real-world example of how I use mdx-prompt for bragdoc.ai - a SaaS app that tracks your work achievements and generates documents from them. This article is not a plug for bragdoc, but I will have to tell you a little about it for the article to make sense. All of the code is open source and can be found on GitHub.
Prompts are arrays of tokens
Our mdx-prompt powered prompt defined above will render into an XML-style prompt like this (slightly truncated for brevity):
<purpose>
You are a careful and attentive assistant who extracts work achievements from source control commit messages. Extract all of the achievements in the commit messages contained within the <user-input>tag. Follow all of the instructions provided below.
</purpose>
<instructions>
<instruction>Consider the chat history and context to understand the full scope of each achievement.</instruction>
<instruction>Each Achievement should be complete and self-contained.</instruction>
<instruction>If the user mentions multiple achievements in a single message, extract them all.</instruction>
// ... more instructions
</instructions>
<input-format title="You are provided with the following inputs:">
<companies>All of the companies that the user works at (or has worked at)</companies>
<projects>All of the projects that the user works on (or has worked on)</projects>
<user-instructions>Any specific instructions from the user to guide the extraction process</user-instructions>
<user-input>The git commits to extract achievements from</user-input>
<repository>Information about the repository the commits are from</repository>
</input-format>
<variables>
<companies>
<company>
<id>74eda7d6-3c69-4f51-a53a-58624bba48f4</id>
<name>Egghead Research</name>
<role>Chief Scientist</role>
<start-date>12/31/2022</start-date>
<end-date>Present</end-date>
</company>
</companies>
<projects>
<project>
<id>94150287-afa1-4caa-aa66-8ad44f31120c</id>
<name>BragDoc.ai</name>
<description>AI-powered self-advocacy tool for tech-savvy individuals.</description>
<status>active</status>
<start-date>12/14/2024</start-date>
<end-date>Present</end-date>
<remote-repo-url>
</remote-repo-url>
</project>
// ... more projects
</projects>
<today>1/17/2025</today>
<user-instructions>If I don't mention a specific project, I'm talking about Brag Doc.</user-instructions>
<user-input>
<commit>
<message>Wrote a bunch of new Evals for extracting achievements and generating documents</message>
<hash>1234</hash>
<author>John Doe - john@doe.com</author>
<date>2023-01-01</date>
</commit>
<commit>
<message>Better styling for the blog pages</message>
"title": "Launched AI Analysis Tool with 95% Accuracy at Quantum Nexus",
"summary": "Developed an AI tool for real-time data analysis with 95% accuracy for Quantum Nexus, playing a pivotal role in Project Orion's success.",
"details": "As part of Project Orion at Quantum Nexus, I was responsible for developing a cutting-edge AI tool focused on real-time data analysis. By implementing advanced algorithms and enhancing the training data sets, the tool reached a 95% accuracy rate. This result significantly supported the company's research objectives and has been positively acknowledged by stakeholders for its robust performance and reliability.",
You are a careful and attentive assistant who extracts work achievements from source control commit messages. Extract all of the achievements in the commit messages contained within the <user-input>tag. Follow all of the instructions provided below.
</purpose>
<instructions>
<instruction>Consider the chat history and context to understand the full scope of each achievement.</instruction>
<instruction>Each Achievement should be complete and self-contained.</instruction>
<instruction>If the user mentions multiple achievements in a single message, extract them all.</instruction>
// ... more instructions
</instructions>
<input-format title="You are provided with the following inputs:">
<companies>All of the companies that the user works at (or has worked at)</companies>
<projects>All of the projects that the user works on (or has worked on)</projects>
<user-instructions>Any specific instructions from the user to guide the extraction process</user-instructions>
<user-input>The git commits to extract achievements from</user-input>
<repository>Information about the repository the commits are from</repository>
</input-format>
<variables>
<companies>
<company>
<id>74eda7d6-3c69-4f51-a53a-58624bba48f4</id>
<name>Egghead Research</name>
<role>Chief Scientist</role>
<start-date>12/31/2022</start-date>
<end-date>Present</end-date>
</company>
</companies>
<projects>
<project>
<id>94150287-afa1-4caa-aa66-8ad44f31120c</id>
<name>BragDoc.ai</name>
<description>AI-powered self-advocacy tool for tech-savvy individuals.</description>
<status>active</status>
<start-date>12/14/2024</start-date>
<end-date>Present</end-date>
<remote-repo-url>
</remote-repo-url>
</project>
// ... more projects
</projects>
<today>1/17/2025</today>
<user-instructions>If I don't mention a specific project, I'm talking about Brag Doc.</user-instructions>
<user-input>
<commit>
<message>Wrote a bunch of new Evals for extracting achievements and generating documents</message>
<hash>1234</hash>
<author>John Doe - john@doe.com</author>
<date>2023-01-01</date>
</commit>
<commit>
<message>Better styling for the blog pages</message>
"title": "Launched AI Analysis Tool with 95% Accuracy at Quantum Nexus",
"summary": "Developed an AI tool for real-time data analysis with 95% accuracy for Quantum Nexus, playing a pivotal role in Project Orion's success.",
"details": "As part of Project Orion at Quantum Nexus, I was responsible for developing a cutting-edge AI tool focused on real-time data analysis. By implementing advanced algorithms and enhancing the training data sets, the tool reached a 95% accuracy rate. This result significantly supported the company's research objectives and has been positively acknowledged by stakeholders for its robust performance and reliability.",
The code we're going to be looking at today is how bragdoc.ai processes git commit histories into work achievements that can then be turned into documents. Basically, if they've installed npm install -g bragdoc, a user can run a command like this:
bash.sh
$ bragdoc extract
bash.sh
$ bragdoc extract
This will grab commit messages from whatever repo you're in and send them up to the bragdoc API, which it then processes into work achievements. The LLM behind this has to consider a bunch of things in doing this, including:
If the user has Projects defined already, which Project are these commits for?
How impactful is each achievement on a scale of 1-3?
When did the achievement happen?
Was it an achievement that happened over a period of time, or a single event?
In order for it to do this, it needs to know about the user's Companies and Projects, the Commits themselves, and the Repository they're in. It may also need to know about recent Achievements that have been tracked. We're using an LLM to take a string prompt and return a structured data response, so we need to provide it with a prompt that tells it what we want it to do.
Moreover, in order to get an LLM to do this highly specialized task for us, we're more likely to achieve success if we one-shot a specialized prompt than if we tried to coax an LLM in the middle of a chat conversation to do it for us. This means we're probably going to use a Router LLM to essentially invoke our specialized prompt as a tool call.
Router LLMs
A lot of AI apps will use a Router LLM model to decide which LLM to use for a given prompt. Bragdoc does this so that we can dispatch to different prompts based on whether we're recording achievements, generating documents, or something else. From the perspective of the Router LLM, the Achievement Extraction process is just a tool that it can call with some input.
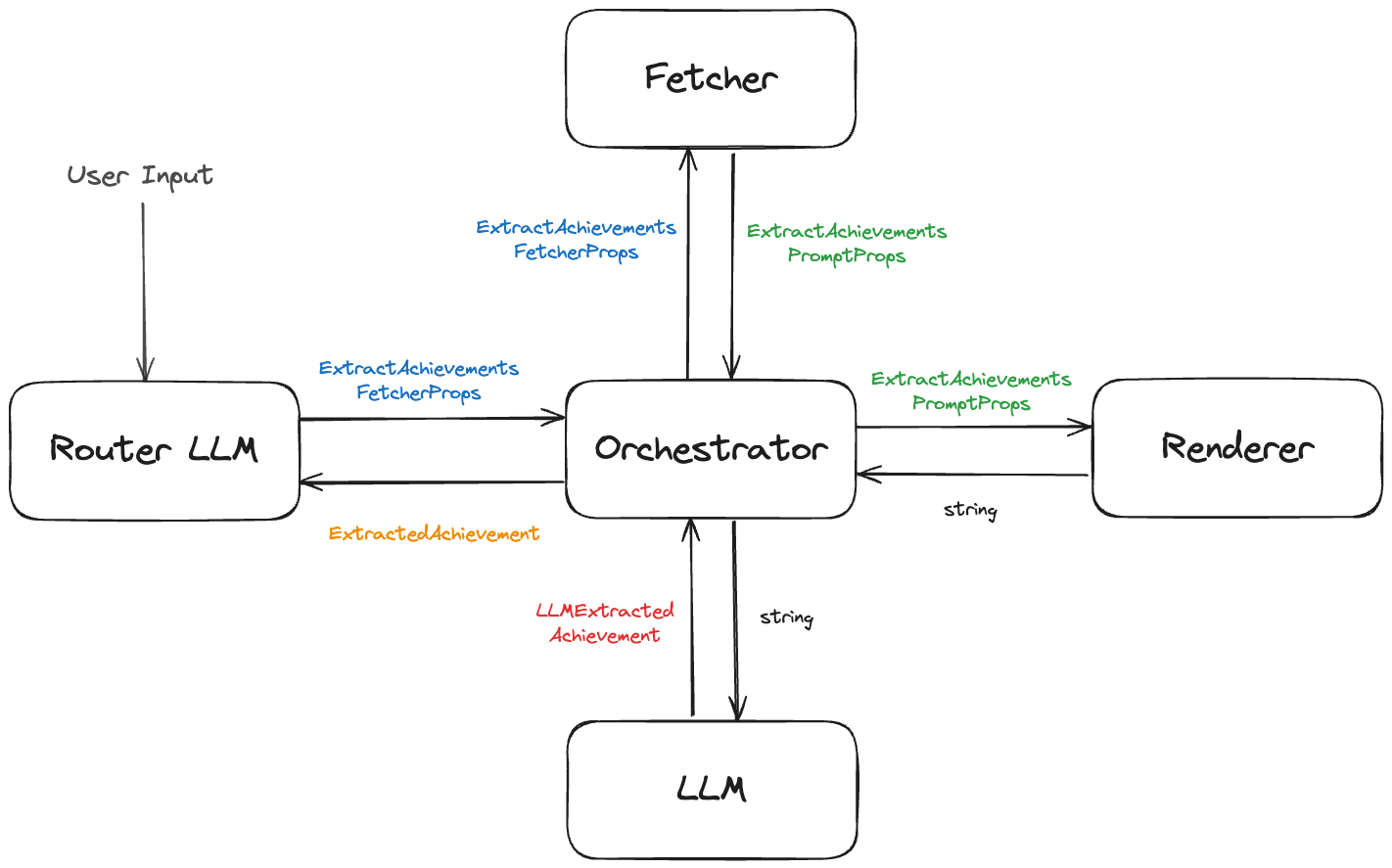
A tool call is not the only way that the achievement extraction process can be invoked, so this means the tool should be a thin wrapper around something else - in this case I'm calling that something else the Orchestrator, which:
gathers all the data required for the Achievement Extraction prompt that wasn't provided by the Router LLM (Fetcher)
renders the prompt using that data (Renderer)
calls the LLM with the prompt, returning the processed response (LLM)
As you can see there are actually at least 5 different types that our data passes through in the Achievement Extraction process:
ExtractAchievementsFetcherProps - the minimal object required to fetch the data for the prompt
ExtractAchievementsPromptProps - the minimal object required to render the prompt
string - the rendered prompt we pass to the LLM
LLMExtractedAchievement - structured output data response from the LLM (needs processing)
ExtractedAchievement - final, processed Achievement objects compatible with our data layer
Conceptually, the types flow around the achievement extraction process like this:
There are five different types that our data passes through in the Achievement Extraction process
The reason for ExtractAchievementsFetcherProps existing is to allow the Router LLM to pass something else the minimum data required to fetch the rest of the data for the prompt. This helps the Router LLM focus on producing the right data for its tool call, and also allows us to have multiple code pathways to generate documents without going through the Router LLM.
The Fetcher may not even need to exist in all instances - here it's just loading the companies and projects for the given user. This centralizes that code in one place, allowing us to reuse it. Its output is ExtractAchievementsPromptProps - the minimal set of data required to render our prompt.
The Orchestrator is a simple function that calls the Fetcher, passes its output to the Renderer, then calls the LLM with the rendered prompt. It also does a little data transformation from the LLMExtractedAchievement to the ExtractedAchievement format that our data layer expects. Again this may not be needed in all cases - in this case it is turning date strings into JS Date objects, as well as inserting some timestamps - stuff we don't want the LLM doing anyway.
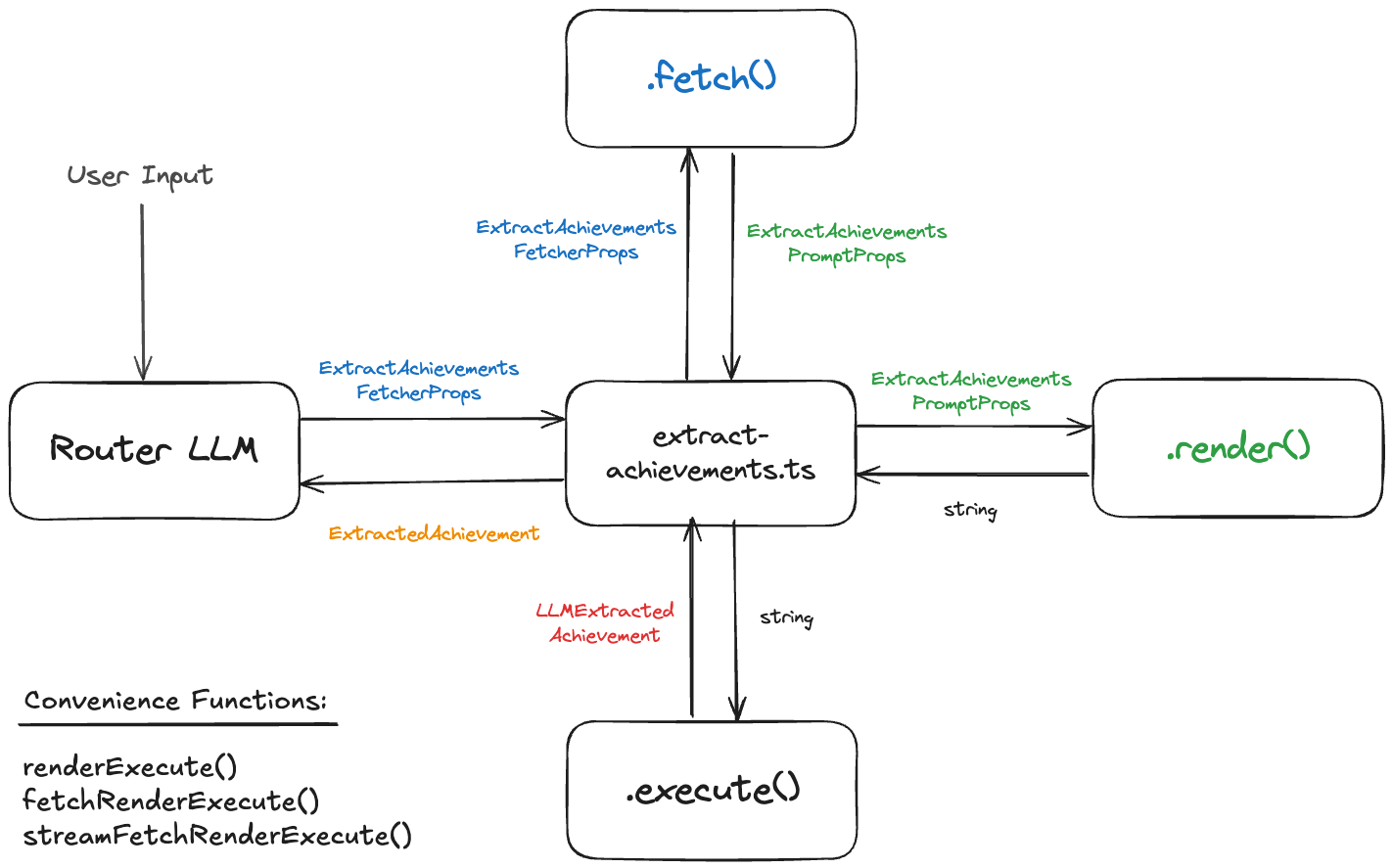
fetch(props) - fetches the data required for the prompt
render(data) - renders the prompt
execute(prompt) - calls the LLM with the prompt and processes the response
renderExecute(data) - renders the prompt and executes it, returning the extracted achievements
fetchRenderExecute(props) - fetch/render/execute, returns the extracted achievements as an array
streamFetchRenderExecute(props) - fetch/render/execute, yielding each extracted achievement as they stream in
Those first three - fetch, render and execute - map directly to the Fetcher/Renderer/LLM conceptual diagram boxes. We can update our diagram with the actual functions, along with the three higher-level functions we've added - renderExecute, fetchRenderExecute, and streamFetchRenderExecute:
The Router LLM just calls streamFetchRenderExecute, which orchestrates the whole process
The fetch(), render(), and execute() functions are super simple. The render() function uses mdx-prompt to render the MDX prompt into a string. The fetch() function just asynchronously does whatever loading is required, and the execute() function uses the excellent Vercel AI SDK to call the LLM and stream back the results:
/**
* Fetches the data necessary to render the Extract Achievements Prompt.
* Given a minimal set of data, prepares the rest of the data required
* for the achievements extraction prompt
*
* @param props ExtractAchievementsFetcherProps
* @returns ExtractAchievementsPromptProps
*/
export async function fetch(props: ExtractAchievementsFetcherProps): Promise<ExtractAchievementsPromptProps> {
const {user, message, chatHistory} = props;
const [projects, companies] = await Promise.all([
getProjectsByUserId(user.id),
getCompaniesByUserId({ userId: user.id }),
]);
return {
message,
chatHistory,
companies,
projects,
user
}
}
/**
* Renders the Extract Achievements Prompt
*
* @param data ExtractAchievementsPromptProps
* @returns string
*/
export async function render(data: ExtractAchievementsPromptProps): Promise<string> {
return await renderMDXPromptFile({
filePath: promptPath,
data,
components
});
}
/**
* Executes the rendered prompt and yields the extracted achievements
eventStart: element.eventStart ? new Date(element.eventStart) : null,
eventEnd: element.eventEnd ? new Date(element.eventEnd) : null,
impactSource: 'llm',
impactUpdatedAt: new Date(),
};
}
}
Fetch
Let's take a closer look at that code then. fetch() is pretty easy:
extract-achievements.ts
/**
* Fetches the data necessary to render the Extract Achievements Prompt.
* Given a minimal set of data, prepares the rest of the data required
* for the achievements extraction prompt
*
* @param props ExtractAchievementsFetcherProps
* @returns ExtractAchievementsPromptProps
*/
export async function fetch(props: ExtractAchievementsFetcherProps): Promise<ExtractAchievementsPromptProps> {
const {user, message, chatHistory} = props;
const [projects, companies] = await Promise.all([
getProjectsByUserId(user.id),
getCompaniesByUserId({ userId: user.id }),
]);
return {
message,
chatHistory,
companies,
projects,
user
}
}
extract-achievements.ts
/**
* Fetches the data necessary to render the Extract Achievements Prompt.
* Given a minimal set of data, prepares the rest of the data required
* for the achievements extraction prompt
*
* @param props ExtractAchievementsFetcherProps
* @returns ExtractAchievementsPromptProps
*/
export async function fetch(props: ExtractAchievementsFetcherProps): Promise<ExtractAchievementsPromptProps> {
const {user, message, chatHistory} = props;
const [projects, companies] = await Promise.all([
getProjectsByUserId(user.id),
getCompaniesByUserId({ userId: user.id }),
]);
return {
message,
chatHistory,
companies,
projects,
user
}
}
All it's doing it taking what the LLM tool call + session data from our Next Auth integration with our API endpoint gave it (ExtractAchievementsFetcherProps) and returning the data required to render the prompt (ExtractAchievementsPromptProps).
types.tsx
// props required to render the Extract Achievements Prompt
export interface ExtractAchievementsPromptProps {
companies: Company[];
projects: Project[];
message: string;
chatHistory: Message[];
user: User;
};
types.tsx
// props required to render the Extract Achievements Prompt
export interface ExtractAchievementsPromptProps {
companies: Company[];
projects: Project[];
message: string;
chatHistory: Message[];
user: User;
};
Having a fetch step means we can call on this piece of LLM functionality from anywhere in our app without needing to re-implement the loading of projects and companies each time we do so.
Render
That ExtractAchievementsPromptProps is the same type we then pass into the Renderer, which is just a function call to mdx-prompt's renderMDXPromptFile() function:
extract-achievements.ts
//load our custom mdx-prompt components like Company and Project
Calling the render() function will return a nicely formatted mixture of text and xml-style tags matching the JSX structure of the prompt.
Execute
The last box on the drawing above is the one labelled LLM - here's how that looks in our code. We're taking a string prompt and using an async generator function to stream the achievements back to the caller as they come in:
extract-achievements.ts
/**
* Executes the rendered prompt and yields the extracted achievements
eventStart: element.eventStart ? new Date(element.eventStart) : null,
eventEnd: element.eventEnd ? new Date(element.eventEnd) : null,
impactSource: 'llm',
impactUpdatedAt: new Date(),
};
}
}
The execute function above is a generator function that yields ExtractedAchievement objects as they come in from the LLM. It's doing the data transformation from LLMExtractedAchievement to ExtractedAchievement that we mentioned earlier.
Convenience Functions
Let's remind ourselves of our diagram:
The 3 higher-level functions are just orchestrations of the lower-level functions
Turning to the 3 other functions we have defined in the extract-achievements.ts file, renderExecute is a wrapper around render() and execute() - it's really useful for Evals, where we want to have more control over the input data than fetch() would allow. fetchRenderExecute just wraps the fetch part as well, returning a Promise that will resolve to the array of extracted Achievements.
The final function - streamFetchRenderExecute - is a generator function that yields each extracted achievement as it comes in from the LLM. This allows us to stream the achievements into the UI as they come in, which is what we do in the Bragdoc app. But all three of these functions are pretty simple orchestrations of the lower-level functions:
/**
* Fetches the data, renders the prompt, and executes the prompt, yielding the extracted achievements
for await (const achievement of execute(await render(data))) {
yield achievement;
}
}
/**
* Fetches the data, renders the prompt, and executes the prompt, returning the extracted achievements
*
* @param input ExtractAchievementsFetcherProps
* @returns Promise<ExtractedAchievement[]>
*/
export async function fetchRenderExecute(input: ExtractAchievementsFetcherProps): Promise<ExtractedAchievement[]> {
const data = await fetch(input);
return await renderExecute(data);
}
/**
* Renders the prompt and executes it, returning the extracted achievements
*
* @param data ExtractAchievementsPromptProps
* @returns Promise<ExtractedAchievement[]>
*/
export async function renderExecute(data: ExtractAchievementsPromptProps): Promise<ExtractedAchievement[]> {
const achievements: ExtractedAchievement[] = [];
for await (const achievement of execute(await render(data))) {
achievements.push(achievement);
}
return achievements;
}
In the actual bragdoc.ai app, we try to give a better UX by streaming the Achievements in to the UI as the LLM returns them, so our tool call is actually calling streamFetchRenderExecute directly so that it can immediately render each Achievement into the UI.
Similarly, for the Evals that we run against this code, we also want to chop and change the pipeline a little bit. From the perspective of our Evals, we want to bypass the Fetcher stage so that we can provide our own ExtractAchievementsPromptProps and test that we got the right ExtractedAchievement objects back.
Testing
Breaking things up like this means we can write effective tests for each step of the process:
Router LLM - an eval that checks the Router is calling the right tool with the right data
Fetcher - unit tests that check the right data is being fetched
Renderer - unit tests that check the right prompt is being rendered
LLM - an eval that checks the LLM is returning the right data for the prompt we feed it
Orchestrator - unit tests that check the right data is being passed between the steps
In this way we've isolated our LLM invocations into tightly-defined functions, so that we can write fast-executing unit tests for everything else in our pipeline, write tight Evals against the LLM parts of the pipeline, passing in well-understood mock data matching the types we've defined.