A few weeks ago I released mdx-prompt, which makes it easy for React developers to create composable, reusable LLM prompts with JSX. Because most AI-heavy apps will use multiple different LLM prompts, and because those prompts often have a lot in common, it's useful to be able to componentize those common elements and reuse them across multiple prompts.
I've applied mdx-prompt pretty much across the board on Task Demon and Bragdoc, which has a dozen or so different LLM prompts at the moment. In a followup post I showed how I use mdx-prompt to build the prompt that extracts achievements from git commit messages for bragdoc.ai - allowing us to build a streaming, live-updating UI powered by a composable, reusable AI prompt.
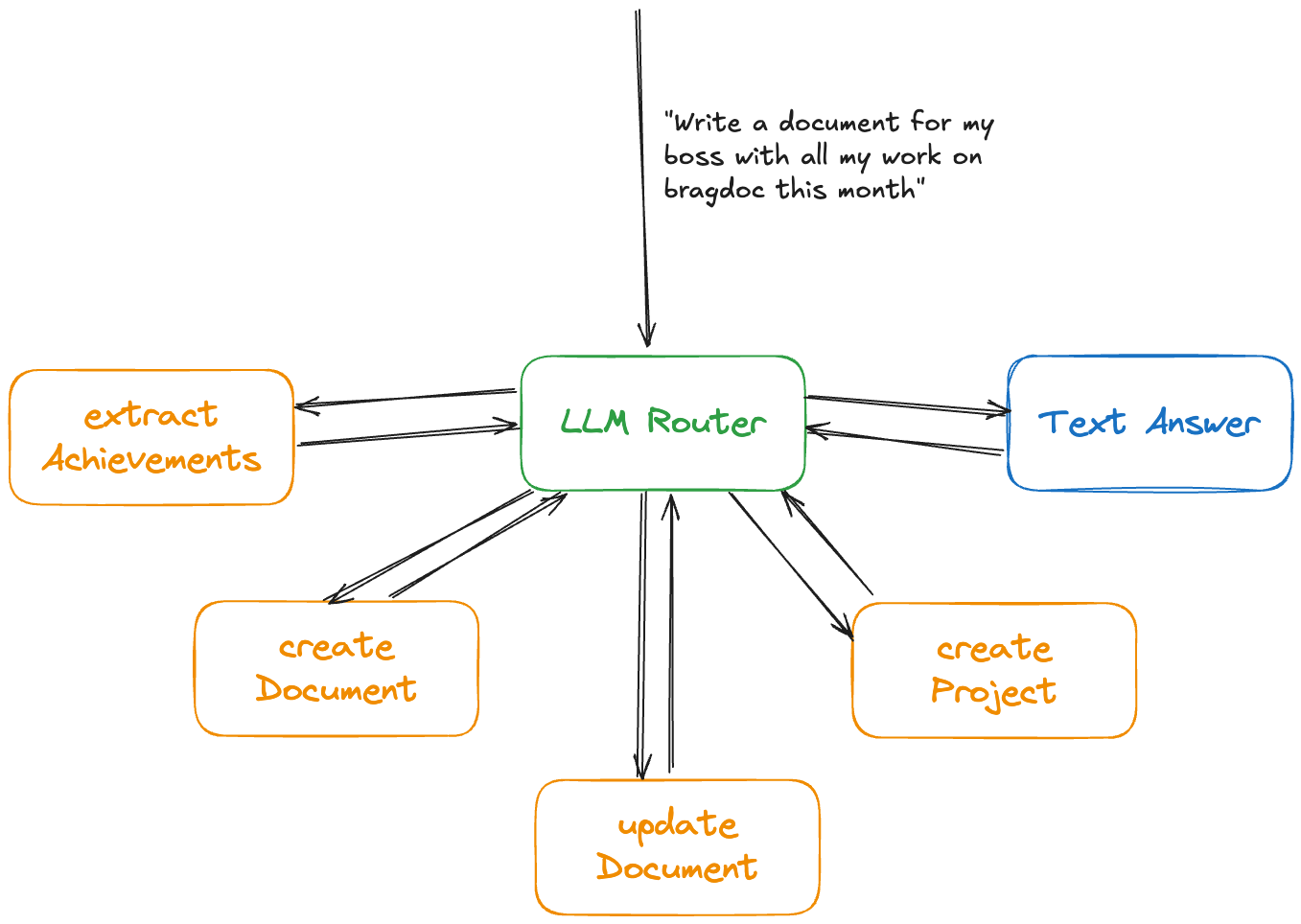
This time we're going to look at the LLM Router that serves as the entrypoint for bragdoc.ai's chatbot. LLM Routers are a common pattern in AI apps, and they can make your users' interactions with your AI app enormously more empowering if you build them properly.
LLM Routers
bragdoc.ai basically does 2 things: extract work achievements from text, and generate documents based on those achievements. We can create highly tailored prompts and AI workflows for each case to make it more likely that our AI will do the right thing. But we also want to support a conversational AI-driven UI, which can achieve most of the things the user can via the UI directly, but with natural language.
That's pretty open-ended - how do we solve this? One powerful tool in our belt is the LLM Router, which is essentially a method where we ask an LLM what kind of message we're dealing with, and then route it to a second LLM call for processing. The first LLM call can be set up to be a general-purpose prompt that understands just enough about your application to be able to delegate to the right tool for the right job.
The secondary LLM calls can be a variety of highly specialized LLM calls or chains of LLM calls that are highly focused on achieving specific objectives. In the example of bragdoc.ai, one of these specialized prompts generates documents based on work achievements.
The LLM Router takes each message from the user and either delegates it or answers it
If you think about what that prompt needs to do, it deviates quite a lot from the general-purpose prompt that we need to be able to delegate to the right tool for the right job, and it's quite specialized. To do its job well, it needs to be fed with a prompt explaining what it is supposed to do, along with all of the project context, along with all of the user's achievements for the period they're talking about.
It's really a kind of a sub-task off of the main conversation thread - "please go write me a document about my achievements for the last 3 months" is something that a user can ask, and it should Just Work, but the main chatbot shouldn't be concerned with making it happen - there's no way it's competent enough to do that. Instead, it should delegate this sub task to another LLM prompt, which can then do its job much more effectively.
Let's see the prompt then
Here's what the LLM Router prompt looks like. At first, it looks huge, but it's not that bad. It has 8 sections - Purpose, Background, schema, Instructions, InputFormat, Tools, Examples and Data.
A lot of it is in an XML-style markup, with some text mixed in. But in essence we first tell the LLM its Purpose ("act as an LLM Router"), then we tell it the Background of the application, the important parts of the database schema, a bunch of explicit Instructions, the InputFormat to expect, the Tools that the LLM can use, Examples of good responses, and the Data itself.
<Purpose>
You are a friendly assistant for bragdoc.ai, which helps users keep a brag document about their achievements at work, as a basis for later generation of performance review documents and weekly summaries for their managers.
You help users track their Achievements at work, and generate weekly/monthly/performance review documents.
You are acting as the Router LLM for bragdoc.ai, so you will receive the whole chat history between yourself and the user, and your job is to act on the most recent message from the user.
</Purpose>
<Background>
This application allows users to log their Achievements at work, organizing them by project and company.
The Achievement data is later used to generate weekly/monthly/performance review documents.
</Background>
Here are the relevant parts of the database schema:
<schema>
<table name="Achievement">
<column name="id" type="uuid" />
<column name="title" type="string" />
<column name="description" type="string" />
<column name="date" type="date" />
<column name="companyId" type="uuid" />
<column name="projectId" type="uuid" />
<column name="eventStart" type="date" />
<column name="eventEnd" type="date" />
<column name="impact" type="number" desc="1, 2, or 3 where 3 is high impact" />
<column name="impactSource" type="string" desc="Impact rated by user or llm" />
</table>
<table name="Company">
<column name="id" type="uuid" />
<column name="name" type="string" />
</table>
<table name="Project">
<column name="id" type="uuid" />
<column name="name" type="string" />
</table>
</schema>
<Instructions>
<Instruction>Keep your responses concise and helpful.</Instruction>
<Instruction>do not call createProject if a project of the same name already exists</Instruction>
<Instruction>If a Project of a similar name exists, ask the user before calling createProject</Instruction>
<Instruction>If the user tells you about things they've done at work, call the extractAchievements tool.</Instruction>
<Instruction>When the user asks you to generate a report, call the createDocument tool (you will be given the Achievements, Companies and Projects data that you need).</Instruction>
<Instruction>Only call the extractAchievements tool once if you detect any number of Achievements in the chat message you examine - the tool will extract all of the achievements in that message and return them to you</Instruction>
</Instructions>
You will be given the following data:
<InputFormat>
<chat-history>The chat history between the user and the chatbot</chat-history>
<user-input>The message from the user</user-input>
<companies>All of the companies that the user works at (or has worked at)</companies>
<projects>All of the projects that the user works on (or has worked on)</projects>
<today>Today's date</today>
</InputFormat>
These are the tools available to you. It may be appropriate to call one or more tools, potentially in a certain order. Other times it will not be necessary to call any tools, in which case you should just reply as normal:
<Tools>
<Background>
Blocks is a special user interface mode that helps users with writing, editing, and other content creation tasks.
When block is open, it is on the right side of the screen, while the conversation is on the left side.
When creating or updating documents, changes are reflected in real-time on the blocks and visible to the user.
This is a guide for using blocks tools: \`createDocument\` and \`updateDocument\`,
which render content on a blocks beside the conversation.
</Background>
<Tool>
<name>extractAchievements</name>
<summary>call this tool if the user tells you about things they've done at work. The extractAchievements tool will automatically be passed the user's message, companies and projects, but as you have also been given the projects and companies, please pass extractAchievements the appropriate companyId and/or projectId, if applicable. A user may be talking about Achievements not linked to a project.</summary>
<when-to-use>
**When to use extractAchievements:**
- When the user is telling you about things they've done at work
- When the user provides an update to an existing Achievement
- Only call the extractAchievements tool once. Do not pass it any arguments
- extractAchievements already has the full conversation history and will use it to generate Achievements
</when-to-use>
<when-not-to-use>
**When NOT to use extractAchievements:**
- When the user is requesting information about existing Achievements
- When the user is requesting information about existing documents
</when-not-to-use>
</Tool>
<Tool>
<name>createDocument</name>
<summary>call this tool if the user asks you to generate a report.</summary>
- The createDocument tool will be passed the user's message and the chat history.
- If the user asks you to generate a report for a specific project or company, please pass the appropriate projectId and/or companyId to the createDocument tool.
- You must also pass the days to the createDocument tool, between 1 and 720. Typically the user will provide you with a time span for the report, but if not, you can assume a span of 30 days, but let the user know that you did so and that they can provide a different span if they want.
- The createDocument tool will generate a document based on the above and return it to you.
<when-to-use>
**When to use \`createDocument\`:**
- For substantial content (>10 lines)
- For content users will likely save/reuse (emails, code, essays, etc.)
- When explicitly requested to create a document
- If you are being asked to write a report, you will be given the user's Achievements, Companies and Projects
- The user may refer specifically to a project, in which case you should set the projectId to that project's ID
- The user may refer specifically to a company, in which case you should set the companyId to that company's ID
- If the user does not refer to a specific company, but does refer to a project, use that project's company ID as the companyId parameter
- If the user requested a specific document title, please use that as the title parameter
- If the user is requesting a specific time period, please supply the number of days as the days parameter. Achievements are are loaded back to N days ago, where N is the number of days requested. These will then be used to create the document
</when-to-use>
<when-not-to-use>
**When NOT to use \`createDocument\`:**
- For informational/explanatory content
- For conversational responses
- When asked to keep it in chat
- Unless the user explicitly requests to create a document
</when-not-to-use>
</Tool>
<Tool>
<name>updateDocument</name>
<summary>call this tool if the user is updating an existing document</summary>
<usage>
**Using \`updateDocument\`:**
- Default to full document rewrites for major changes
- Use targeted updates only for specific, isolated changes
- Follow user instructions for which parts to modify
Do not update document right after creating it. Wait for user feedback or request to update it.
</usage>
</Tool>
<Tool>
<name>createProject</name>
<summary>Creates a new Project</summary>
<when-to-use>
Call this tool if the user either explicitly asks you to create a new project, or if it is clear from the context that the user would like you to do so. For example, if the user says "I started a new project called Project Orion today, so far I got the website skeleton in place and basic auth too", you should create a new project called Project Orion, before calling extractAchievements
</when-to-use>
</Tool>
</Tools>
Here are some examples of messages from the user and the tool selection or response you should make:
<Examples>
<Example>
User: I fixed up the bugs with the autofocus dashboard generation and we launched autofocus version 2.1 this morning.
Router LLM: Call extractAchievements tool
</Example>
<Example>
User: Write a weekly report for my work on Project X for the last 7 days.
Router LLM: Call createDocument tool, with the days set to 7, and the correct projectId and companyId
</Example>
<Example>
User: I started a new project called Project Orion today, so far I got the website skeleton in place and basic auth too. Please create a new project called Project Orion and call extractAchievements
Router LLM: Call createProject tool, and then call extractAchievements tool
You are a friendly assistant for bragdoc.ai, which helps users keep a brag document about their achievements at work, as a basis for later generation of performance review documents and weekly summaries for their managers.
You help users track their Achievements at work, and generate weekly/monthly/performance review documents.
You are acting as the Router LLM for bragdoc.ai, so you will receive the whole chat history between yourself and the user, and your job is to act on the most recent message from the user.
</Purpose>
<Background>
This application allows users to log their Achievements at work, organizing them by project and company.
The Achievement data is later used to generate weekly/monthly/performance review documents.
</Background>
Here are the relevant parts of the database schema:
<schema>
<table name="Achievement">
<column name="id" type="uuid" />
<column name="title" type="string" />
<column name="description" type="string" />
<column name="date" type="date" />
<column name="companyId" type="uuid" />
<column name="projectId" type="uuid" />
<column name="eventStart" type="date" />
<column name="eventEnd" type="date" />
<column name="impact" type="number" desc="1, 2, or 3 where 3 is high impact" />
<column name="impactSource" type="string" desc="Impact rated by user or llm" />
</table>
<table name="Company">
<column name="id" type="uuid" />
<column name="name" type="string" />
</table>
<table name="Project">
<column name="id" type="uuid" />
<column name="name" type="string" />
</table>
</schema>
<Instructions>
<Instruction>Keep your responses concise and helpful.</Instruction>
<Instruction>do not call createProject if a project of the same name already exists</Instruction>
<Instruction>If a Project of a similar name exists, ask the user before calling createProject</Instruction>
<Instruction>If the user tells you about things they've done at work, call the extractAchievements tool.</Instruction>
<Instruction>When the user asks you to generate a report, call the createDocument tool (you will be given the Achievements, Companies and Projects data that you need).</Instruction>
<Instruction>Only call the extractAchievements tool once if you detect any number of Achievements in the chat message you examine - the tool will extract all of the achievements in that message and return them to you</Instruction>
</Instructions>
You will be given the following data:
<InputFormat>
<chat-history>The chat history between the user and the chatbot</chat-history>
<user-input>The message from the user</user-input>
<companies>All of the companies that the user works at (or has worked at)</companies>
<projects>All of the projects that the user works on (or has worked on)</projects>
<today>Today's date</today>
</InputFormat>
These are the tools available to you. It may be appropriate to call one or more tools, potentially in a certain order. Other times it will not be necessary to call any tools, in which case you should just reply as normal:
<Tools>
<Background>
Blocks is a special user interface mode that helps users with writing, editing, and other content creation tasks.
When block is open, it is on the right side of the screen, while the conversation is on the left side.
When creating or updating documents, changes are reflected in real-time on the blocks and visible to the user.
This is a guide for using blocks tools: \`createDocument\` and \`updateDocument\`,
which render content on a blocks beside the conversation.
</Background>
<Tool>
<name>extractAchievements</name>
<summary>call this tool if the user tells you about things they've done at work. The extractAchievements tool will automatically be passed the user's message, companies and projects, but as you have also been given the projects and companies, please pass extractAchievements the appropriate companyId and/or projectId, if applicable. A user may be talking about Achievements not linked to a project.</summary>
<when-to-use>
**When to use extractAchievements:**
- When the user is telling you about things they've done at work
- When the user provides an update to an existing Achievement
- Only call the extractAchievements tool once. Do not pass it any arguments
- extractAchievements already has the full conversation history and will use it to generate Achievements
</when-to-use>
<when-not-to-use>
**When NOT to use extractAchievements:**
- When the user is requesting information about existing Achievements
- When the user is requesting information about existing documents
</when-not-to-use>
</Tool>
<Tool>
<name>createDocument</name>
<summary>call this tool if the user asks you to generate a report.</summary>
- The createDocument tool will be passed the user's message and the chat history.
- If the user asks you to generate a report for a specific project or company, please pass the appropriate projectId and/or companyId to the createDocument tool.
- You must also pass the days to the createDocument tool, between 1 and 720. Typically the user will provide you with a time span for the report, but if not, you can assume a span of 30 days, but let the user know that you did so and that they can provide a different span if they want.
- The createDocument tool will generate a document based on the above and return it to you.
<when-to-use>
**When to use \`createDocument\`:**
- For substantial content (>10 lines)
- For content users will likely save/reuse (emails, code, essays, etc.)
- When explicitly requested to create a document
- If you are being asked to write a report, you will be given the user's Achievements, Companies and Projects
- The user may refer specifically to a project, in which case you should set the projectId to that project's ID
- The user may refer specifically to a company, in which case you should set the companyId to that company's ID
- If the user does not refer to a specific company, but does refer to a project, use that project's company ID as the companyId parameter
- If the user requested a specific document title, please use that as the title parameter
- If the user is requesting a specific time period, please supply the number of days as the days parameter. Achievements are are loaded back to N days ago, where N is the number of days requested. These will then be used to create the document
</when-to-use>
<when-not-to-use>
**When NOT to use \`createDocument\`:**
- For informational/explanatory content
- For conversational responses
- When asked to keep it in chat
- Unless the user explicitly requests to create a document
</when-not-to-use>
</Tool>
<Tool>
<name>updateDocument</name>
<summary>call this tool if the user is updating an existing document</summary>
<usage>
**Using \`updateDocument\`:**
- Default to full document rewrites for major changes
- Use targeted updates only for specific, isolated changes
- Follow user instructions for which parts to modify
Do not update document right after creating it. Wait for user feedback or request to update it.
</usage>
</Tool>
<Tool>
<name>createProject</name>
<summary>Creates a new Project</summary>
<when-to-use>
Call this tool if the user either explicitly asks you to create a new project, or if it is clear from the context that the user would like you to do so. For example, if the user says "I started a new project called Project Orion today, so far I got the website skeleton in place and basic auth too", you should create a new project called Project Orion, before calling extractAchievements
</when-to-use>
</Tool>
</Tools>
Here are some examples of messages from the user and the tool selection or response you should make:
<Examples>
<Example>
User: I fixed up the bugs with the autofocus dashboard generation and we launched autofocus version 2.1 this morning.
Router LLM: Call extractAchievements tool
</Example>
<Example>
User: Write a weekly report for my work on Project X for the last 7 days.
Router LLM: Call createDocument tool, with the days set to 7, and the correct projectId and companyId
</Example>
<Example>
User: I started a new project called Project Orion today, so far I got the website skeleton in place and basic auth too. Please create a new project called Project Orion and call extractAchievements
Router LLM: Call createProject tool, and then call extractAchievements tool
This prompt will be run against a given chat session between a user and the LLM Router. This gets rendered in the <ChatHistory /> component, with the latest message being emphasized in the <UserInput /> component;
Based on the user message and the chat history, the LLM is asked to select a tool to use, or to reply directly to the user. The way it's implemented in bragdoc, some of those tool calls are actually the secondary LLMs that are invoked in the LLM Router pattern.
The generate document tool is one such example - the user posts a message to the chat conversation, which then invokes a tool which spins up an inner LLM prompt that generates the document without spending much of the outer LLM's context on the effort, and getting a better outcome at the same time.
How the Prompt Gets Called
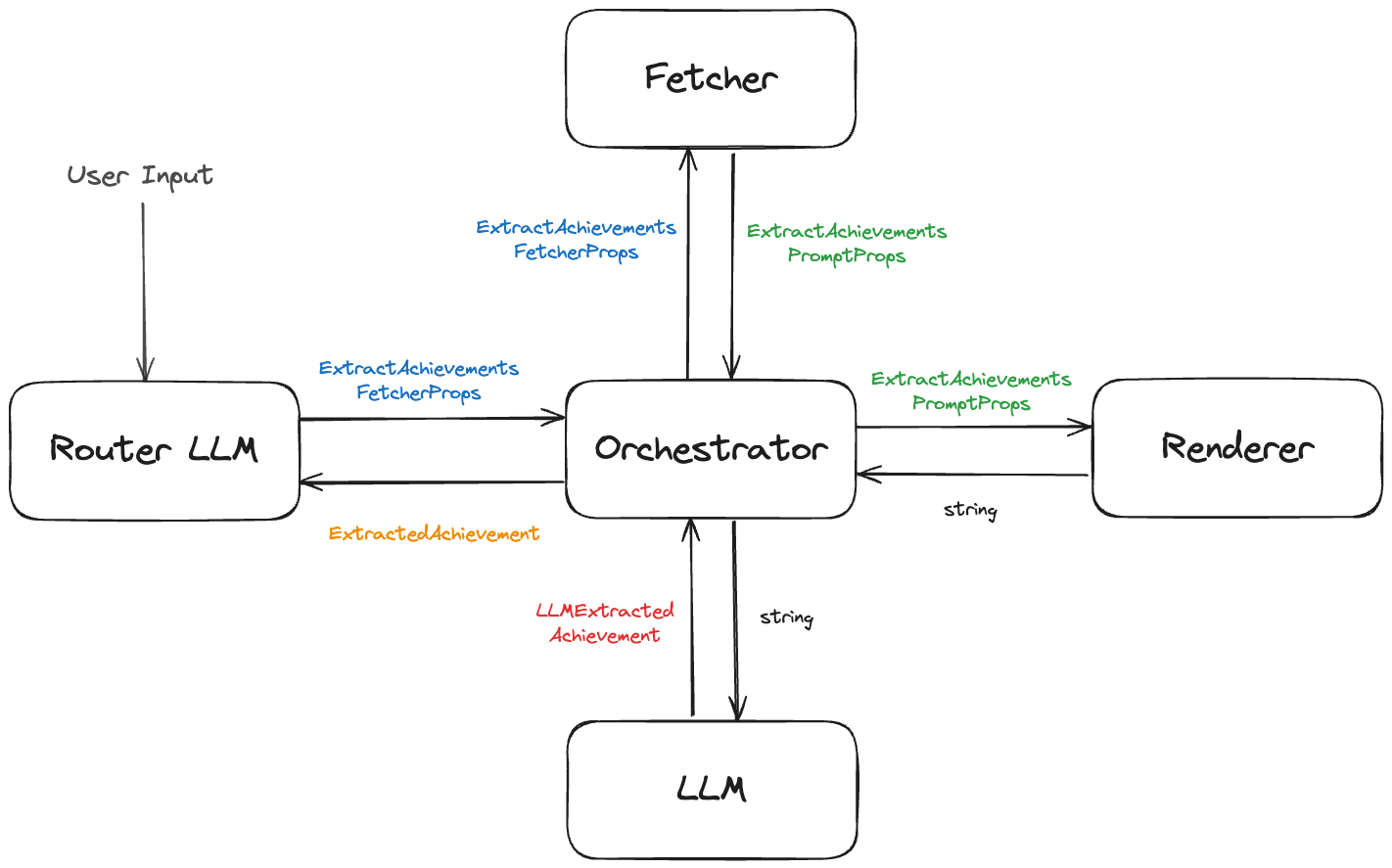
As you can tell from the lengthy prompt above, this prompt expects quite a bit of data to be passed in. It wants the recent chat history, including the current message, plus the user's companies and projects. In a recent post on mdx-prompt I described the fetch/render/execute cycle that I tend to apply for almost all of my LLM calls. Those are:
fetch: given a minimal amount of data, load the data required to render the prompt
render: given the data loaded in the fetch step, render the prompt to the UI
execute: given the rendered prompt, run it and return the result
The llm-router.ts file in bragdoc-ai implements this pattern for the main Bragdoc LLM Router, and it's a good example of how to use mdx-prompt with NextJS. That's a 400 line file, though most of that is tool definitions.
Let's take a look at our 3 functions, starting with fetch:
Pretty trivial. We do this so that we can call the LLM Router from many different parts of our app without having to re-implement the loading of companies and projects each time we do so.
* Renders the LLM router prompt using the provided data.
*
* @param {LlmRouterPromptProps} data - The data including user details, companies, projects, etc
* @returns {Promise<string>} The rendered prompt.
*/
export async function render(data: LlmRouterPromptProps) {
return await renderMDXPromptFile({
filePath: promptPath,
data,
components,
});
}
Equally trivial, it's just passing the data from fetch into mdx-prompt for rendering.
The big boy is the execute function, chiefly because it currently inlines all of the tools (which is not great architecture as the tools are not easily testable that way, but that's a topic for another day). All this does is send our rendered prompt plus 3 tools (createDocument, updateDocument, and extractAchievements) to the LLM, and stream the results back to the user.
All 3 of those tool calls are in fact secondary LLM calls - they're also mdx-prompt prompts, and follow the same fetch/render/execute cycle as the LLM Router does. And that's all an LLM Router really is - just an LLM something that dispatches queries to other LLMs.
llm-router.ts
/**
* Executes the LLM router with the provided prompt and data.
*
* @param {LlmRouterExecuteProps} props - The properties including prompt, stream text options, etc
* @returns {Promise<JSONValue>} The result of the execution.
*/
export function execute({
prompt,
streamTextOptions,
data,
onEvent,
tools,
}: LlmRouterExecuteProps) {
const eventCallback = data.onEvent || onEvent;
//This is a tool of the LLM Router, but it's a tool that calls another LLM prompt
description: "Create a document based on the User's achievements",
parameters: z.object({
title: z.string().describe('The title of the document'),
days: z
.number()
.int()
.min(1)
.max(720)
.describe('The number of days ago to load Achievements from'),
projectId: z
.string()
.optional()
.describe('The ID of the project that the user is talking about'),
companyId: z
.string()
.optional()
.describe(
"The ID of the company that the user is talking about (use the project's company if not specified and the project has a companyId)"
),
}),
execute: tools?.createDocument || createDocument,
},
updateDocument: {
description: 'Update a document with the given description',
parameters: z.object({
id: z.string().describe('The ID of the document to update'),
description: z
.string()
.describe('The description of changes that need to be made'),
}),
execute: tools?.updateDocument || updateDocument,
},
},
});
}
That's about a hundred lines of code but it's pretty easy stuff. And that's really all there is to it.
Integrating into NextJS
This is also fairly straightforward. I use the excellent Vercel AI SDK for all of my work with LLMs, and this one is no exception. The actual source code of the api/chat/route.ts is here, but here's a slightly slimmed down version:
route.ts
import { streamFetchRenderExecute } from "@/lib/ai/llm-router";
export const maxDuration = 120;
export async function POST(request: Request) {
// truncated all other the auth and data loading code. All we need is userMessage
//onEvent is our own custom callback, implemented in streamFetchRenderExecute,
//where each message is JSON suitable to be streamed back to the client
onEvent: (item: any) => {
streamingData.append(item);
},
streamTextOptions: {
onFinish: async ({ response }) => {
try {
//save messages to the database
await saveMessages({... truncated for brevity ... });
} catch (error) {
console.error("Failed to save chat");
console.log(error);
}
streamingData.close();
},
experimental_telemetry: {
isEnabled: true,
functionId: "stream-text",
},
},
});
return result.toDataStreamResponse({
data: streamingData,
});
}
That's really all it is. We have a simple function called streamFetchRenderExecute, which just calls our fetch, render and execute functions in order, returning us what the execute function returns, which is just the Vercel AI SDK's streamText function.
In the UI, we use useChat inside our chat.tsx component, which works out of the box with streamText, so at this point we're pretty much done. If the LLM wants to respond in text, that gets streamed back to the UI in the normal way, and if it needs instead to dispatch to another LLM call, that all happens transparently under the covers, with the StreamData object used to stream tool call progress/results back too.
There Can Be (more than) Only One
You don't need to limit yourself to a single LLM Router. In fact, it's often a good idea to have more than one. Task Demon is an order of magnitude more sophisticated than Bragdoc and currently uses no fewer than 6 different LLM Routers - one for each of the different Agents in the system. For now this article is long enough already, but I'll be writing about that in the future.
Share Post:
What to Read Next
To further explore the capabilities of mdx-prompt, consider reading mdx-prompt: Real World Example Deep Dive, which provides more context and implementation strategies with practical examples. Additionally, for an introduction to creating composable LLM prompts, mdx-prompt: Composable LLM Prompts with JSX offers a comprehensive guide to integrating with JSX effectively.