Recently, I've been focused on blending AI and TypeScript within React applications. My latest article, NarratorAI: Trainable AI assistant for Node and React, introduces a new open-source project aimed at enhancing user experiences with intelligent assistance. This builds on earlier discussions about content recommendations, as seen in AI Content Recommendations with TypeScript and the practical implementations in ReadNext: AI Content Recommendations for Node JS.
Additionally, I've explored the intricacies of Retrieval-Augmented Generation (RAG) in Easy RAG for TypeScript and React Apps, which lays the groundwork for developing advanced recommendation systems. If you're interested in further enhancing your React applications, don't miss my insights on Loading Fast and Slow: async React Server Components and Suspense and Using Server Actions with Next JS. Each piece contributes to my ongoing quest to streamline development with modern technologies.
frameit.dev - fast and free video thumbs, title cards and OG images
As a developer who occasionally creates technical content, I've always found thumbnail creation to be a friction point. I don't have a design background, and I don't want to pay for Photoshop or Canva Pro just to make a few YouTube thumbnails. I'd often spend more time fiddling with graphics software than actually creating the content.
What I wanted was a simple tool that would give me repeatable, correctly-sized and attractive images to use for video thumbnails, title cards, Open Graph images, and the like. I'm a big fan of the excalidraw approach: a simple, client-side app that runs in the browser, does one thing well, and does not require any information from its users.
Enter frameit.dev:

Initially vibe-coded as a way to quickly get a few consistent video titles created, it ended up being useful enough that I've been slowly iterating on it to make it better. The code is all open source, with a hosted version running at frameit.dev.
Eval-Driven Design with NextJS and mdx-prompt
In the previous article, we went on a deep dive into how I use mdx-prompt on bragdoc.ai to write clean, composable LLM prompts using good old JSX. In that article as well as the mdx-prompt announcement article, I promised to talk about Evals and their role in helping you architect and build AI apps that you can actually prove work.
Evals are to LLMs what unit tests are to deterministic code. They are an automated measure of the degree to which your code functions correctly. Unit tests are generally pretty easy to reason about, but LLMs are usually deployed to do non-deterministic and somewhat fuzzy things. How do we test functionality like that?
In the last article we looked at the extract-achievements.ts file from bragdoc.ai, which is responsible for extracting structured work achievement data using well-crafted LLM prompts. Here's a reminder of what that Achievement extract process looks like, with its functions to fetch, render and execute the LLM prompts.
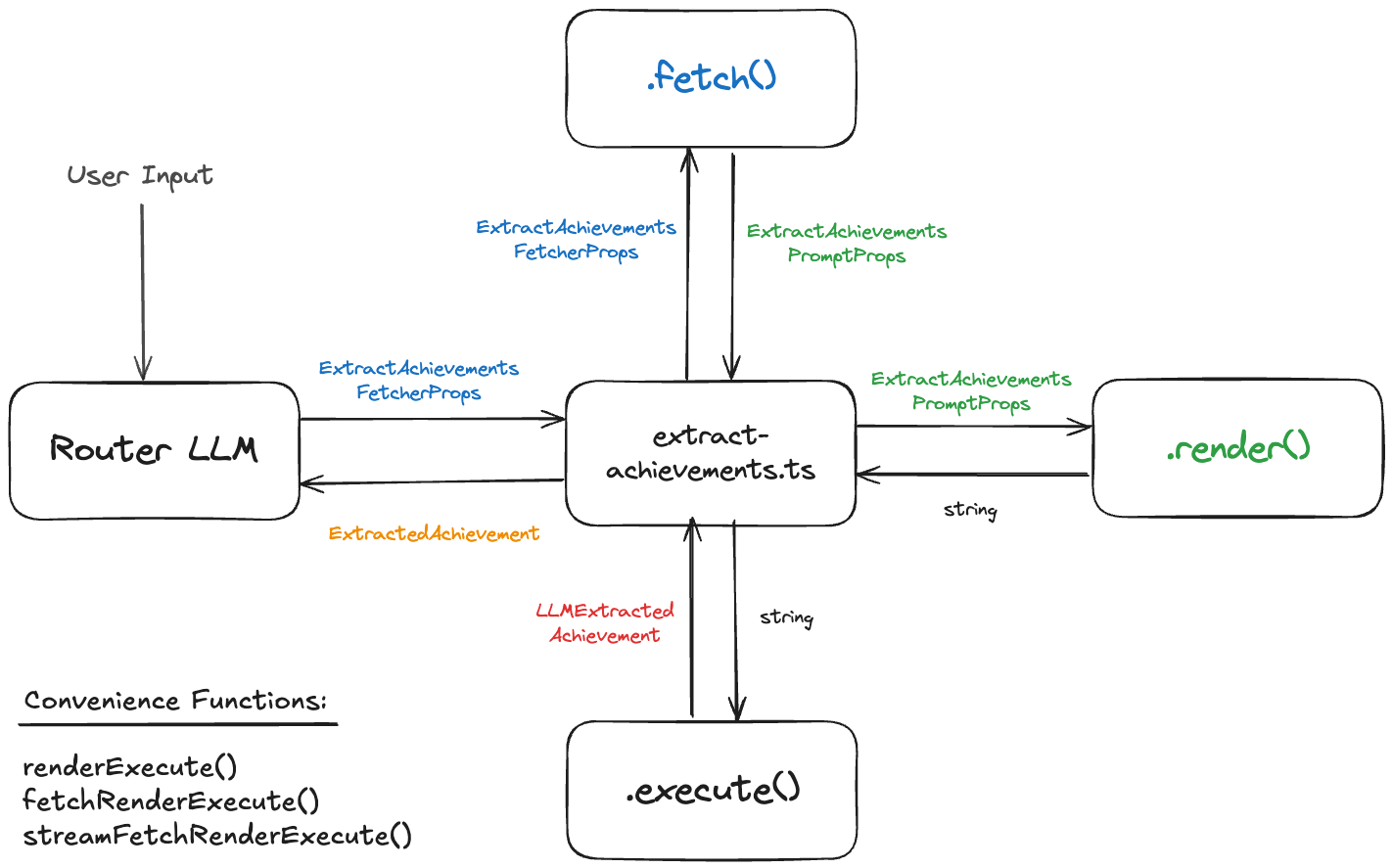
When it comes right down to it, when we say we want to test this LLM integration, what we're trying to test is render() plus execute(), or our convenience function renderExecute. This allows us to craft our own ExtractAchievementsPromptProps and validate that we get reasonable-looking ExtractedAchievement objects back.
ExtractAchievementsPromptProps is just a TS interface that describes all the data we need to render the LLM prompt to extract achievements from a chat session. It looks like this:
mdx-prompt: Real World Example Deep Dive
I just released mdx-prompt, which is a simple library that lets you write familiar React JSX to render high quality prompts for LLMs. Read the introductory article for more general info if you didn't already, but the gist is that we can write LLM Prompts with JSX/MDX like this:
This ought to look familiar to anyone who's ever seen React code. This project was born of a combination of admiration for the way IndyDevDan and others structure their LLM prompts, and frustration with the string interpolation approaches that everyone takes to generating prompts for LLMs.
In the introductory post I go into some details on why string interpolation-heavy functions are not great for prompts. It's a totally natural thing to want to do - once you've started programming against LLM interfaces, you want to start formalizing the mechanism by which you generate the string that is the prompt. Before long you notice that many of your app's prompts have a lot of overlap, and you start to think about how you can reuse the parts that are the same.
Lots of AI-related libraries try to help you here with templating solutions, but they often feel clunky. I really, really wanted to like Langchain, but I lost a day of my life trying to get it to render a prompt that I could have done in 5 minutes with JSX. JSX seems to be a pretty good fit for this problem, and anyone who knows React (a lot of people) can pick it up straight away. mdx-prompt helps React developers compose their LLM prompts with the familiar syntax od JSX.
mdx-prompt: Composable LLM Prompts with JSX
I'm a big fan of IndyDevDan's YouTube channel. He has greatly expanded my thinking when it comes to LLMs. One of the interesting things he does is write many of his prompts with an XML structure, like this:
I really like this structure. Prompt Engineering has been a dark art for a long time. We're suddenly programming using English, which is hilariously imprecise as a programming language, and it feels not quite like "real engineering".
But prompting is actually not programming in English, it's programming in tokens. It just looks like English, so it's easy to fall into the trap of giving it English. But we're not constrained to that at all actually - we can absolutely format our prompts more like XML and reap some considerable rewards:
- It's easier for humans to reason about prompts in this format
- It's easier to reuse content across prompts
- It's easier to have an LLM generate a prompt in this format (see IndyDevDan's metaprompt video)
We've seen this before
I've started migrating many of my prompts to this format, and noticed a few things:
- It organized my thinking around what data the prompt needs
- Many prompts could or should use the same data, but repeat fetching/rendering logic each time
How I built bragdoc.ai in 3 weeks
As we start 2025, it's never been faster to get a SaaS product off the ground. The frameworks, vendors and tools available make it possible to build in weeks what would have taken months or years even just a couple of years ago.
But it's still a lot.
Even when we start from a base template, we still need to figure out our data model, auth, deployment strategy, testing, email sending/receiving, internationalization, mobile support, GDPR, analytics, LLM evals, validation, UX, and a bunch more things:

This morning I launched bragdoc.ai, an AI tool that tracks the work you do and writes things like weekly updates & performance review documents for you. In previous jobs I would keep an achievements.txt file that theoretically kept track of what I worked on each week so that I could make a good case for myself come review time. Bragdoc scratches my own itch by keeping track of that properly with a chatbot who can also make nice reports for me to share with my manager.
But this article isn't much about bragdoc.ai itself, it's about how a product like it can be built in 3 weeks by a single engineer. The answer is AI tooling, and in particular the Windsurf IDE from Codeium.
In fact, this article could easily have been titled "Use Windsurf or Die". I've been in the fullstack software engineering racket for 20 years, and I've never seen a step-change in productivity like the one heralded by Cursor, Windsurf, Repo Prompt and the like. We're in the first innings of a wave of change in how software is built.
NarratorAI: Trainable AI assistant for Node and React
Every word in every article on this site was, for better or worse, written by me: a real human being. Recently, though, I realized that various pages on the site kinda sucked. Chiefly I'm talking about the Blog home page, tag pages like this one for articles tagged with AI and other places where I could do with some "meta-content".
By meta-content I mean content about content, like the couple of short paragraphs that summarize recent posts for a tag, or the outro text that now appears at the end of each post, along with the automatically generated Read Next recommendations that I added recently using ReadNext.
If you go look at the RSC tag, for example, you'll see a couple of paragraphs that summarize what I've written about regarding React Server Components recently. The list of article excerpts underneath it is a lot more approachable with that high-level summary at the top. Without the intro, the page just feels neglected and incomplete.
But the chances of me remembering to update that intro text every time I write a new post about React Server Components are slim to none. I'll write it once, it'll get out of date, and then it will be about as useful as a chocolate teapot. We need a better way. Ideally one that also lets me play by watching the AI stream automatically generated content before my very eyes:

ReadNext: AI Content Recommendations for Node JS
Recently I posted about AI Content Recommendations with TypeScript, which concluded by introducing a new NPM package I've been working on called ReadNext. This post is dedicated to ReadNext, and will go into more detail about how to use ReadNext in Node JS, React, and other JavaScript projects.
What it is
ReadNext is a Node JS package that uses AI to generate content recommendations. It's designed to be easy to use, and can be integrated into any Node JS project with just a few lines of code. It is built on top of LangChain, and delegates to an LLM of your choice for summarizing your content to generate recommendations. It runs locally, does not require you to deploy anything, and has broad support for a variety of content types and LLM providers.
ReadNext is not an AI itself, nor does it want your money, your data or your soul. It's just a library that makes it easy to find related content for developers who use JavaScript as their daily driver. It's best used at build time, and can be integrated into your CI/CD pipeline to generate recommendations for your content as part of your build process.
How to use it
Get started in the normal way:
Configure a ReadNext instance:
Index your content:
AI Content Recommendations with TypeScript
In the last post, we used TypeScript to create searchable embeddings for a corpus of text content and integrated it into a chat bot. But chat bots are the tomato ketchup of AI - great as an accompaniment to something else, but not satisfying by themselves. Given that we now have the tools to vectorize our documents and perform semantic searches against them, let's extend that to generate content recommendations for our readers.
At the bottom of each of my blog articles are links to other posts that may be interesting to the reader based on the current article. The lo-fi way this was achieved was to find all the other posts which overlapped on one or more tags and pick the most recent one.
Quite often that works ok, but I'm sure you can think of ways it could pick a sub-optimal next article. Someone who knows the content well could probably pick better suggestions at least some of the time. LLMs are really well-suited to tasks like this, and should in theory have several advantages over human editors (such as not forgetting what I wrote last week).
We want to end up with some simple UI like this, with one or more suggestions for what to read next:
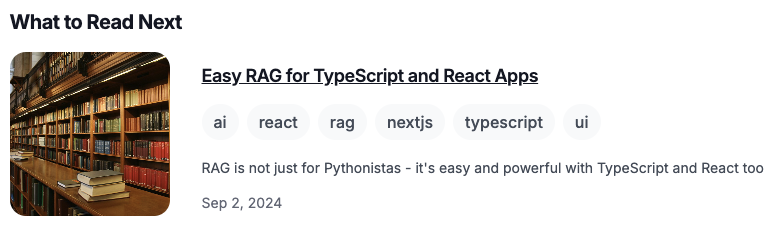
So how do we figure out which content to recommend based on what you're looking at?
Easy RAG for TypeScript and React Apps
This is the first article in a trilogy that will go through the process of extracting content from a large text dataset - my blog in this case - and making it available to an LLM so that users can get answers to their questions without searching through lots of articles along the way.
Part 1 will cover how to process your text documents for easy consumption by an LLM, throw those embeddings into a vector database, and then use that to help answer the user's questions. There are a million articles about this using Python, but I'm principally a TypeScript developer so we'll focus on TS, React and NextJS.
Part 2 covers how to make an AI-driven "What to Read Next" component, which looks at the content of an document (or blog post, in this case) and performs a semantic search through the rest of the content to rank which other posts are most related to this one, and suggest them.
Part 3 will extend this idea by using InformAI to track which articles the user has looked at and attempt to predictively generate suggested content for that user, personalizing the What to Read Next component while keeping the reader completely anonymous to the system.
Let's RAG
About a week ago I released InformAI, which allows you to easily surface the state of your application UI to an LLM in order to help it give more relevant responses to your user. In that intro post I threw InformAI into the blog post itself, which gave me a sort of zero-effort poor man's RAG, as the LLM could see the entire post and allow people to ask questions about it.
That's not really what InformAI is intended for, but it's nice that it works. But what if we want to do this in a more scalable and coherent way? This blog has around 100 articles, often about similar topics. Sometimes, such as when I release open source projects like InformAI, it's one of the only sources of information on the internet about the given topic. You can't ask ChatGPT what InformAI is, but with a couple of tricks we can transparently give ChatGPT access to the answer so that it seems like it magically knows stuff it was never trained on.
Loading Fast and Slow: async React Server Components and Suspense
When the web was young, HTML pages were served to clients running web browser software that would turn the HTML text response into rendered pixels on the screen. At first these were static HTML files, but then things like PHP and others came along to allow the server to customize the HTML sent to each client.
CSS came along to change the appearance of what got rendered. JavaScript came along to make the page interactive. Suddenly the page was no longer the atomic unit of the web experience: pages could modify themselves right there inside the browser, without the server being in the loop at all.
This was good because the network is slow and less than 100% reliable. It heralded a new golden age for the web. Progressively, less and less of the HTML content was sent to clients as pre-rendered HTML, and more and more was sent as JSON data that the client would render into HTML using JavaScript.
This all required a lot more work to be done on the client, though, which meant the client had to download a lot more JavaScript. Before long we were shipping MEGABYTES of JavaScript down to the web browser, and we lost the speediness we had gained by not reloading the whole page all the time. Page transitions were fast, but the initial load was slow. Megabytes of code shipped to the browser can multiply into hundreds of megabytes of device memory consumed, and not every device is your state of the art Macbook Pro.
Single Page Applications ultimately do the same thing as that old PHP application did - render a bunch of HTML and pass it to the browser to render. The actual rendered output is often a few kilobytes of plain text HTML, but we downloaded, parsed and executed megabytes of JavaScript to generate those few kilobytes of HTML. What if there was a way we could keep the interactivity of a SPA, but only send the HTML that needs to be rendered to the client?
Using Server Actions with Next JS
React and Next.js introduced Server Actions a while back, as a new/old way to call server-side code from the client. In this post, I'll explain what Server Actions are, how they work, and how you can use them in your Next.js applications. We'll look at why they are and are not APIs, why they can make your front end code cleaner, and why they can make your backend code messier.
Everything old is new again
In the beginning, there were <form>s. They had an action, and a method, and when you clicked the submit button, the browser would send a request to the server. The server would then process the request and send back a response, which could be a redirect. The action was the URL of the server endpoint, and the method was usually either GET or POST.
Then came AJAX, and suddenly we could send requests to the server without reloading the page. This was a game-changer, and it opened up a whole new world of possibilities for building web applications. But it also introduced a lot of complexity, as developers had to manage things like network requests, error handling, and loading states. We ended up building React components like this:
This code is fine, but it's a lot of boilerplate for something as simple as submitting a form. It's also not very readable, as the logic for handling the form submission is mixed in with the UI code. Wouldn't it be nice if we could go back to the good old days of <form>s, but without the page reload?
Using ChatGPT to generate ChatGPT Assistants
OpenAI dropped a ton of cool stuff in their Dev Day presentations, including some updates to function calling. There are a few function-call-like things that currently exist within the Open AI ecosystem, so let's take a moment to disambiguate:
- Plugins: introduced in March 2023, allowed GPT to understand and call your HTTP APIs
- Actions: an evolution of Plugins, makes it easier but still calls your HTTP APIs
- Function Calling: Chat GPT understands your functions, tells you how to call them, but does not actually call them
It seems like Plugins are likely to be superseded by Actions, so we end up with 2 ways to have GPT call your functions - Actions for automatically calling HTTP APIs, Function Calling for indirectly calling anything else. We could call this Guided Invocation - despite the name it doesn't actually call the function, it just tells you how to.
That second category of calls is going to include anything that isn't an HTTP endpoint, so gives you a lot of flexibility to call internal APIs that never learned how to speak HTTP. Think legacy systems, private APIs that you don't want to expose to the internet, and other places where this can act as a highly adaptable glue.