
Easy RAG for TypeScript and React Apps
RAG is not just for Pythonistas - it's easy and powerful with TypeScript and React too
In the last post, we used TypeScript to create searchable embeddings for a corpus of text content and integrated it into a chat bot. But chat bots are the tomato ketchup of AI - great as an accompaniment to something else, but not satisfying by themselves. Given that we now have the tools to vectorize our documents and perform semantic searches against them, let's extend that to generate content recommendations for our readers.
At the bottom of each of my blog articles are links to other posts that may be interesting to the reader based on the current article. The lo-fi way this was achieved was to find all the other posts which overlapped on one or more tags and pick the most recent one.
Quite often that works ok, but I'm sure you can think of ways it could pick a sub-optimal next article. Someone who knows the content well could probably pick better suggestions at least some of the time. LLMs are really well-suited to tasks like this, and should in theory have several advantages over human editors (such as not forgetting what I wrote last week).
We want to end up with some simple UI like this, with one or more suggestions for what to read next:
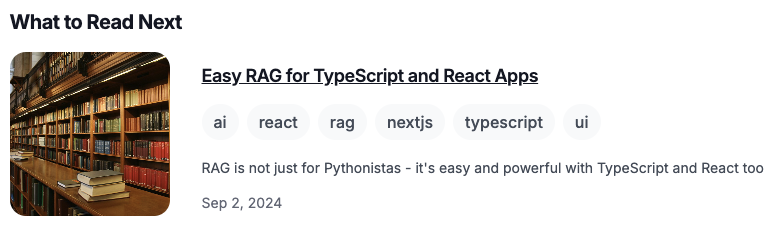
So how do we figure out which content to recommend based on what you're looking at?
We already saw how we compare the "meaning" of a user question (a string) with the "meaning" of our content (a bunch of other strings). This is basically the same problem - comparing the meaning of a text document to the meaning of N other text documents.
But we run into the same problem we ran into last time: the embedding model usually has a fairly low maximum token count, so you can't feed an entire article into it unless the article is below that boundary. In the previous article, we solved this by chunking the document content into smaller sections. But that wouldn't be a valid approach this time because we want to consider the whole article content, not just some chunk of it.
One answer to this is to pass our content through an automated summarization process first, guaranteeing that that article summary will be under the embedding model token limit while also preserving enough of the content to make sure that the suggestions are good ones.
There are several approaches to doing this, and I recommend Lan Chu's article on working around LLM token limit issues for a good overview of the options. At its simplest, though, we can do something like this:
Now we can make an embedding for our article summary:
This code has all of the error handling and other stuff stripped out make it easy to understand what's going on. In theory we now just need to iterate over all of our articles, generate the summaries, generate the embeddings, and then we can do a vector search to find the most similar articles to the one we're currently looking at.
There are about a hundred articles on this blog at the moment. To calculate the most relevant next article for each one, we therefore need to:
| Task | Time | Dollars |
|---|---|---|
| Summarize 100 articles | ~240s | $0.02 |
| Vectorize 100 articles | ~75s | < $0.01 |
| Similarity search 100 articles | ~30s | $0* |
The $0.03 I can live with, but the 6 minutes is less cool. And that's just for 100 articles. If you have a larger corpus, you're going to be waiting a long time for this to finish. There are 2 obvious things to do to make that better:
Typically, once an article is written, it's not going to change (unless I made an embarrassing mistake and want to secretly fix it). So we can cache the summaries and their embeddings and only recompute them if the article changes. However, every time an article is published, it becomes a candidate for the best "Read Next" article for all of the other ones, so we have to perform the similarity search for all of the articles again.
This stuff is involved enough that I ended up writing a TypeScript library to make it easier to work with. It's called ReadNext and it's available on GitHub and NPM. It provides a simple API to index your articles and retrieve the most relevant ones based on a given article.
Under the covers it does all the things we just talked about - summarization, embedding and vector search. It uses FAISS for the vector search, which is a neat, mature open source project that does this kind of thing really well. It caches the summaries and embeddings onto the file system so that you don't have to do them again, and it parallelizes the summarization and vectorization to make it faster.
I'll go into more detail on how to use it in the next post, but for now, here's a quick example of how you might use it:
Now we can generate the recommendations for a given article:
Which will give us a response like this:
Lower scores indicate closer relatedness. Once you have this data, you can use it to generate a list of links to suggest to the user. Because the scores won't change unless the content changes, you can cache the results and only recompute them when the content changes, so the whole thing is eminently cacheable and well-suited to static site generation.
The old method I was using was simply showing you the most recent article that had at least one tag in common with the current one. That was ok much of the time, but I have a bunch of Ext JS posts from 2009 that were recommending recent articles on RAG, solely because the RAG articles are the most recent ones that are tagged with "ui". They're not really related at all.
To test it out I ran ReadNext to generate recommendations for each article, then compared the FAISS score for ReadNext's recommendation to the score for the most recent article with at least one tag in common. In only 4% of cases was the old method suggesting the same article as ReadNext; in the other 96% of cases ReadNext suggested an article it thought was more relevant.
Here's a chart showing the difference in scores between the old method and ReadNext. It's ordered by the difference in scores, so the articles on the left are the ones where ReadNext thought the old method was most wrong:
The purple bars are the scores for the recommended article from ReadNext. The green bars are the delta between the tag-based recommendation method and the contextual AI generated recommendation. The taller the purple bar, the less confident ReadNext is in its suggestion. The taller the green bar, the more wrong ReadNext thinks the old method was.
You can see by hovering over the bars to the left edge of the chart that the articles where ReadNext thinks its recommendations are much better than the old way tend to be ones where the old method was suggesting a recent article with a tag in common but completely unrelated content - like recommending a RAG article to read next after an article on the ancient Ext.ux.Printer plugin.
Wherever you see a tall purple bar in the chart above, it means that ReadNext is not very confident in its suggestion. This is because the article in question is not very similar to any of the other articles in the corpus. Sometimes there are just no particularly similar articles to pick, so in those cases we could fall back to the old method of picking the most recent article with a tag in common.
Looking at the data in the chart above, we could set a threshold of 0.9 or 1 for the FAISS score, and if ReadNext can't find a suggestion above that threshold, we could fall back to the old method. This would give us the best of both worlds - the ability to suggest more relevant articles when they're available, but not to suggest something completely unrelated when there's nothing better to suggest.
If we wanted to prioritize newer content, we could apply a decay modifier to increase the candidate article's score by an amount proportional to the difference in publication date. This would make newer articles more likely to be recommended, but only when they're actually relevant.
We'll get a bit more into this in the next post, where I'll show you how to use ReadNext in your own projects, along with how I used it for the RSC Examples site to generate related React Server Component examples.
Consider exploring ReadNext: AI Content Recommendations for Node JS, which details using a Node JS package to enhance content recommendations with AI. Additionally, Introducing InformAI - Easy & Useful AI for React apps provides insights into integrating AI features seamlessly within React applications.
RAG is not just for Pythonistas - it's easy and powerful with TypeScript and React too
ReadNext is a new npm package that creates content recommendations for your Node JS projects.
InformAI lets AI see what your user sees in your React apps
Markdown is a really nice way to write content like blog posts and other long-form content, with live components inside
herdctl runs Claude Code agents securely in Docker, with schedules and chat
Learn moreAI-powered work documentation for career advancement
Start free demoherdctl runs Claude Code agents securely in docker, with optional schedules and chat
→ Read moremdx-prompt lets you write reusable and composable LLM prompts using JSX
→ Read morebragdoc.ai is an open source Next JS AI SaaS app for tracking your work
→ Read morereact-auto-intl automatically internationalizes and translates React and Next JS apps
→ Read moreNarratorAI creates AI-powered content like intros and search result summaries
→ Read moreInformAI allows AI to access and understand the information in your React components
→ Read moreReadNext creates AI-powered content recommendations for your blog or other content
→ Read moreI've built things on the web for 20 years, and used JavaScript before it was cool.
I've been working for myself since early 2023, going wherever my heart takes me - mostly playing with AI and UI.