herdctl: Composable Fleets of Claude Agents
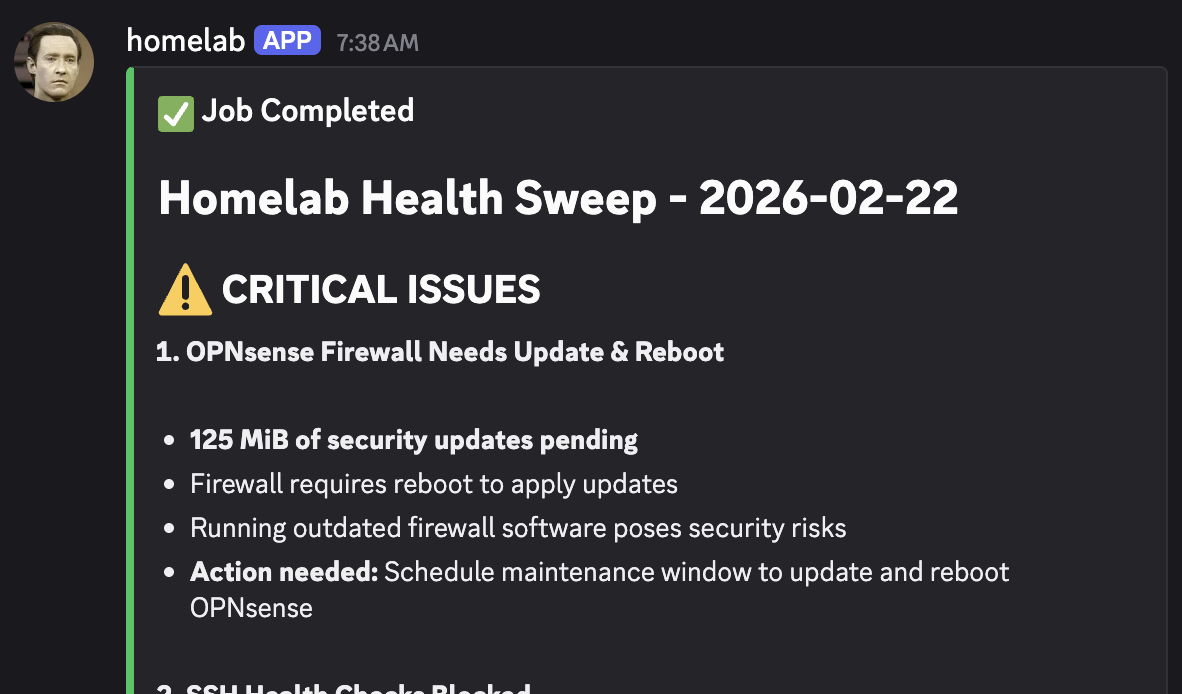
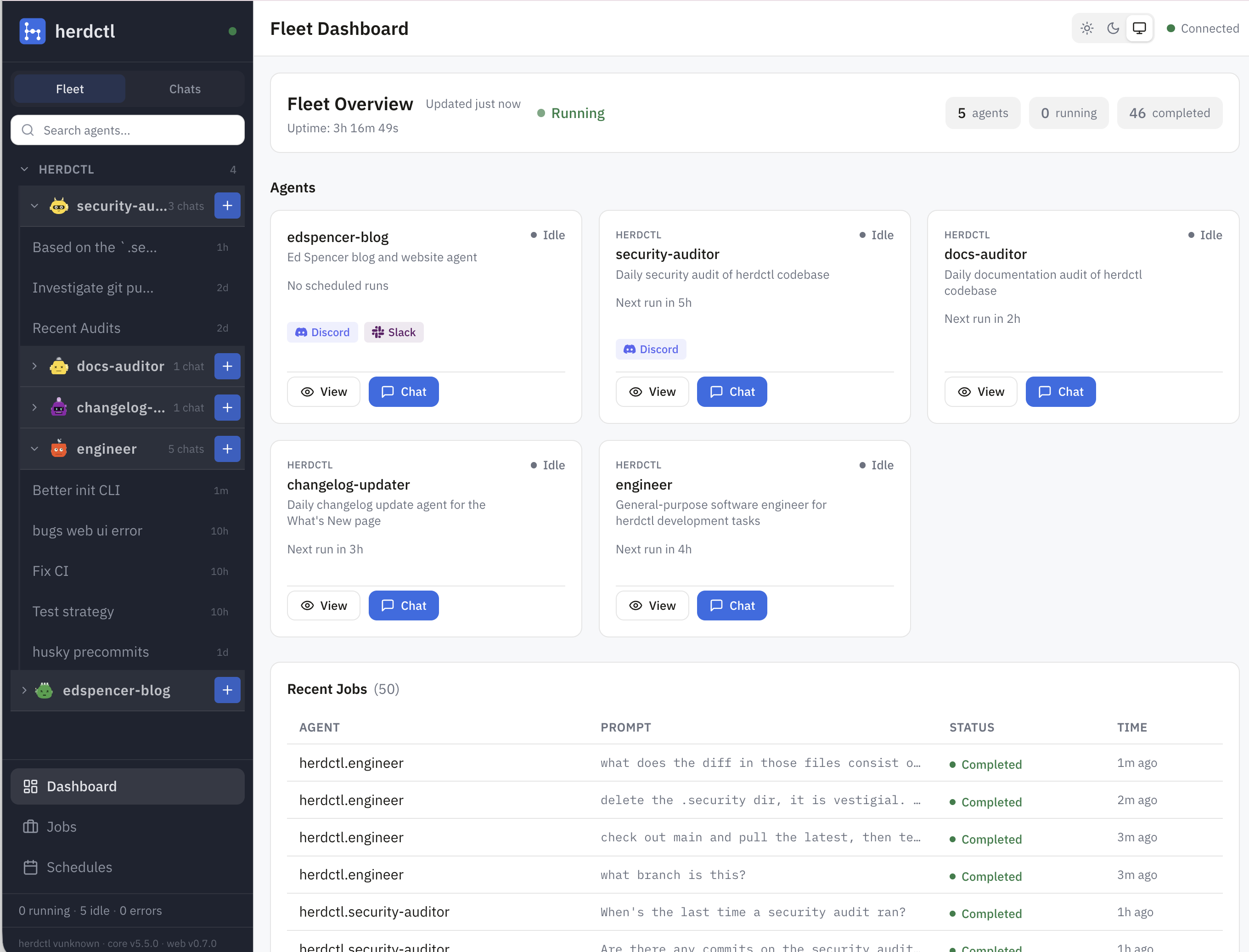
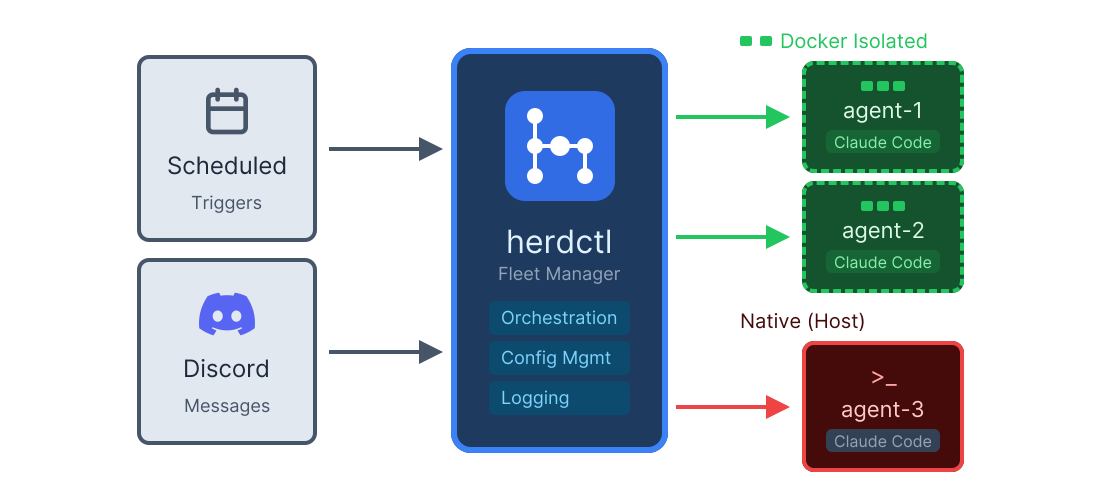
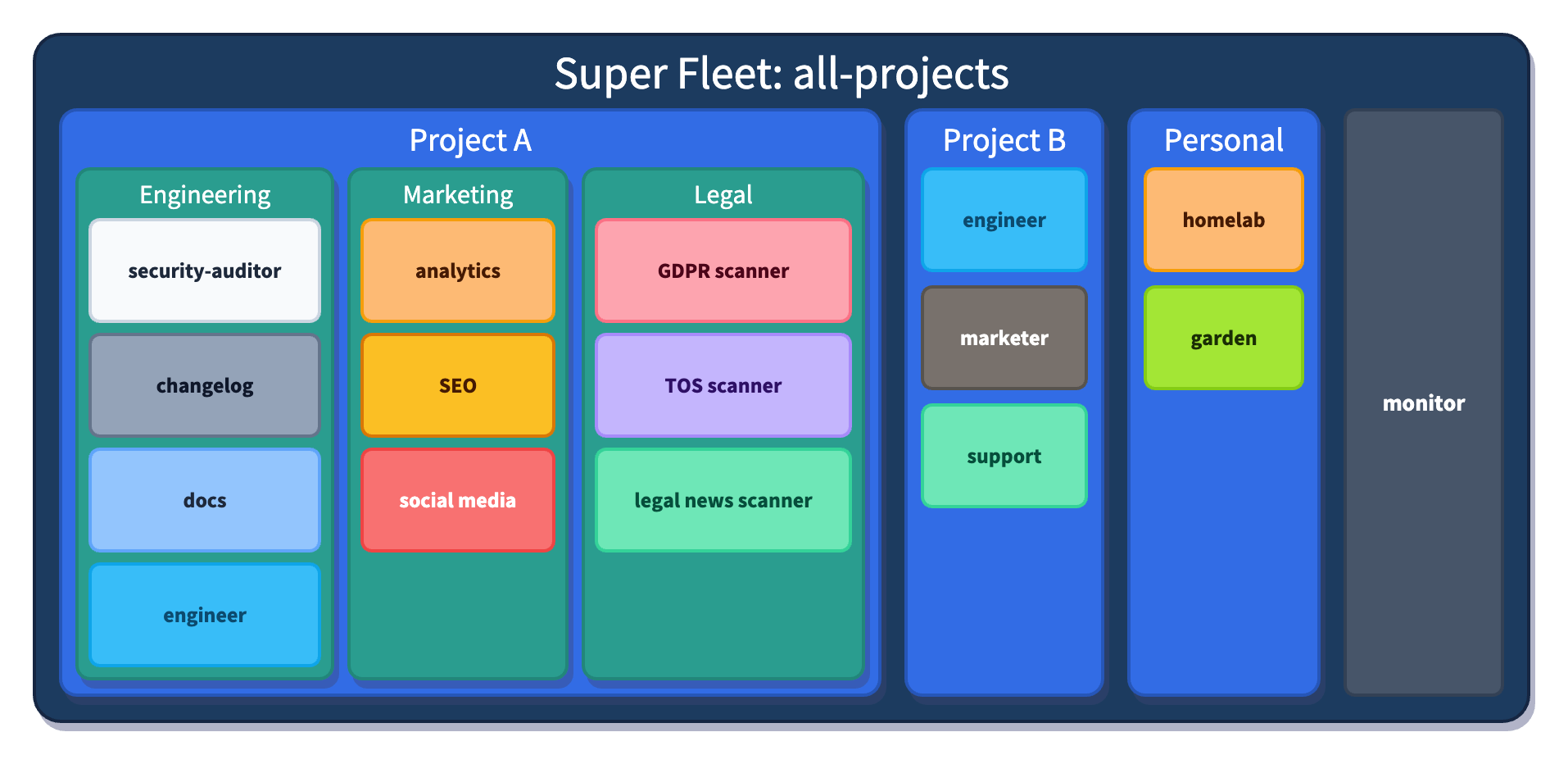
I justed added support for Composable Fleets to herdctl. As I build herdctl into more projects, I increasingly find myself creating a fleet of agents per project, and wanted a way to run them all from a central place so that I can juggle a bunch of things at once.