Evals are to LLMs what unit tests are to deterministic code. They are an automated measure of the degree to which your code functions correctly. Unit tests are generally pretty easy to reason about, but LLMs are usually deployed to do non-deterministic and somewhat fuzzy things. How do we test functionality like that?
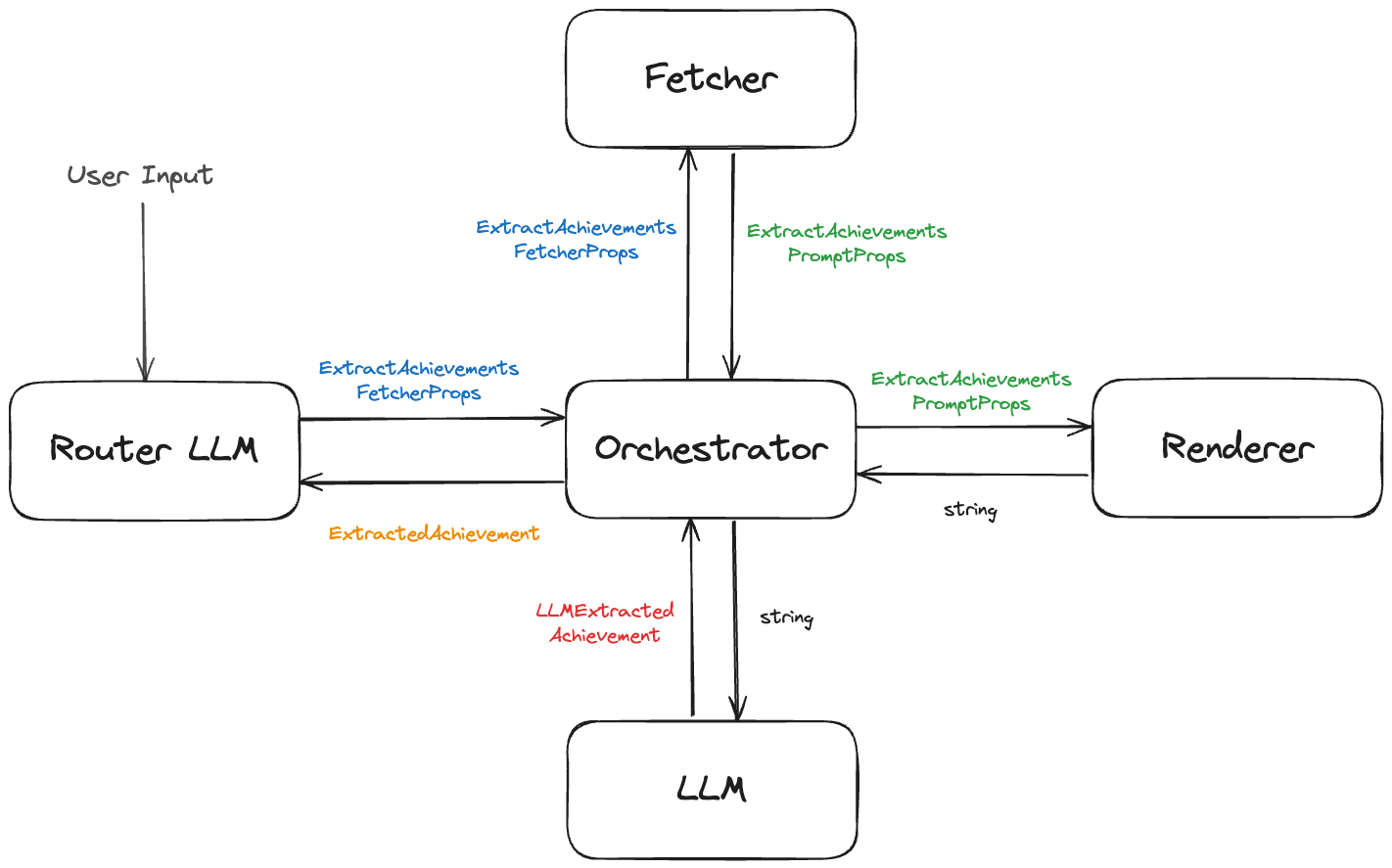
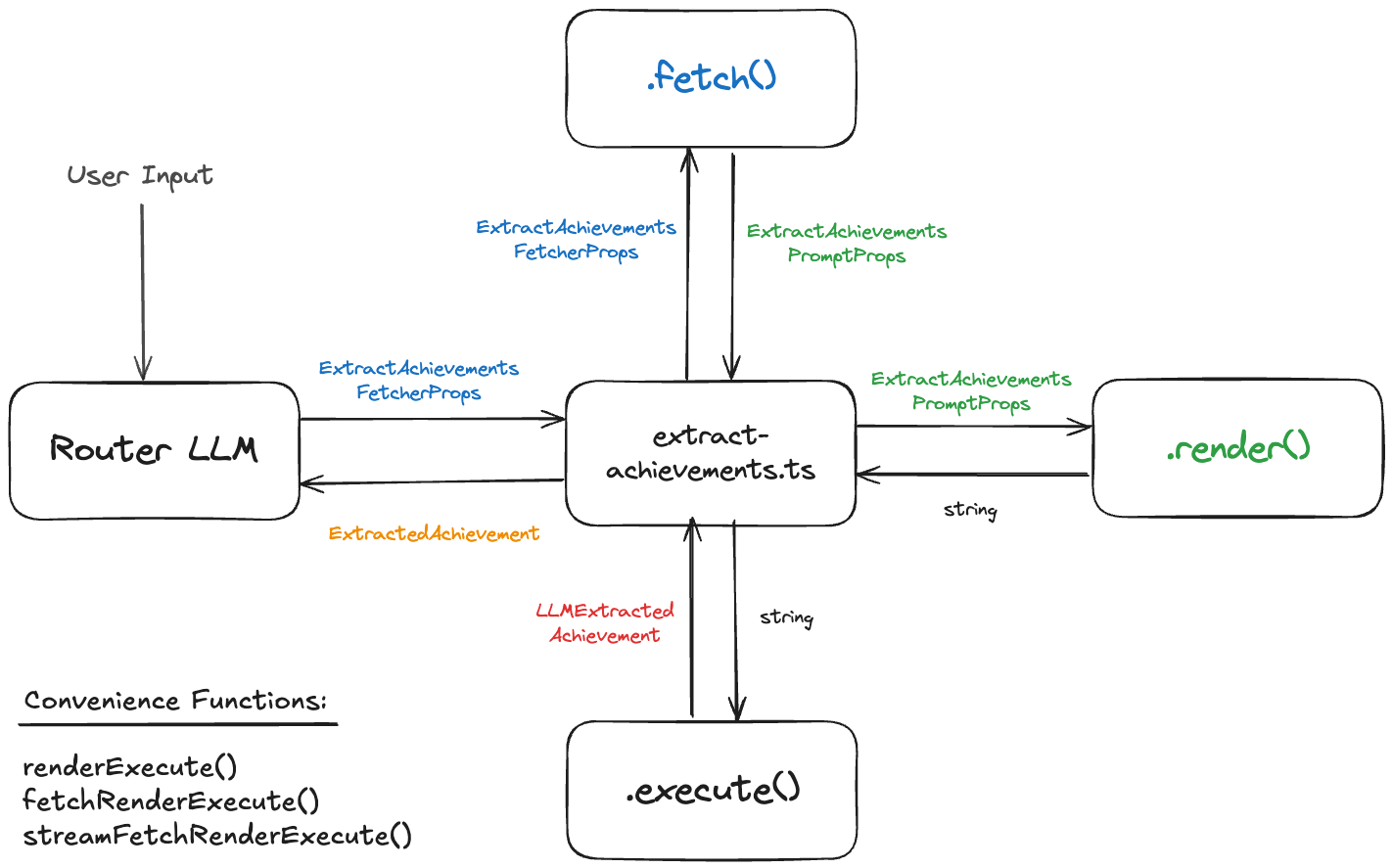
In the last article we looked at the extract-achievements.ts file from bragdoc.ai, which is responsible for extracting structured work achievement data using well-crafted LLM prompts. Here's a reminder of what that Achievement extract process looks like, with its functions to fetch, render and execute the LLM prompts.
The 3 higher-level functions are just orchestrations of the lower-level functions
When it comes right down to it, when we say we want to test this LLM integration, what we're trying to test is render() plus execute(), or our convenience function renderExecute. This allows us to craft our own ExtractAchievementsPromptProps and validate that we get reasonable-looking ExtractedAchievement objects back.
ExtractAchievementsPromptProps is just a TS interface that describes all the data we need to render the LLM prompt to extract achievements from a chat session. It looks like this:
types.ts
//props required to render the Extract Achievements Prompt
export interface ExtractAchievementsPromptProps {
companies: Company[];
projects: Project[];
message: string;
chatHistory: Message[];
user: User;
}
types.ts
//props required to render the Extract Achievements Prompt
export interface ExtractAchievementsPromptProps {
companies: Company[];
projects: Project[];
message: string;
chatHistory: Message[];
user: User;
}
ExtractedAchievement is equally basic - just a subset of our Achievement type (which is itself just a drizzle model).
types.ts
// the type of Achievement emitted by the LLM wrapper (not saved to db yet)
// basically what the LLM sent back plus a couple of fields like impactUpdatedAt
export type ExtractedAchievement = Pick<
Achievement,
| 'title'
| 'summary'
| 'details'
| 'eventDuration'
| 'eventStart'
| 'eventEnd'
| 'companyId'
| 'projectId'
| 'impact'
| 'impactSource'
| 'impactUpdatedAt'
>;
types.ts
// the type of Achievement emitted by the LLM wrapper (not saved to db yet)
// basically what the LLM sent back plus a couple of fields like impactUpdatedAt
export type ExtractedAchievement = Pick<
Achievement,
| 'title'
| 'summary'
| 'details'
| 'eventDuration'
| 'eventStart'
| 'eventEnd'
| 'companyId'
| 'projectId'
| 'impact'
| 'impactSource'
| 'impactUpdatedAt'
>;
Our execute function - the function that actually runs a rendered LLM prompt - is an async generator that yields ExtractedAchievement objects. Our Eval will need to collect those ExtractedAchievement objects and compare them to the Achievements it expects to see.
extract-achievements.tsx
/**
* Executes the rendered prompt and yields the extracted achievements
eventStart: element.eventStart ? new Date(element.eventStart) : null,
eventEnd: element.eventEnd ? new Date(element.eventEnd) : null,
impactSource: 'llm',
impactUpdatedAt: new Date(),
};
}
}
Crafting a Scenario
So now that we're familiar with the shapes of the data at the start and the end of the Eval process, we can start to put together a scenario to test our LLM code. This is probably the hardest part - there are infinitely many approaches and you probably need more than one of them.
But one's better than none so let's imagine a scenario for a user who is an engineer, has a couple of companies and projects, and tells the bragdoc AI a couple of things that they've been working on. First up we'll need some data to represent this user, their companies and projects. Here's a snippet of some fake data that we can use to represent this user:
data/user.ts
import type { User } from '@/lib/db/schema';
import { v4 as uuidv4 } from 'uuid';
export const user: User = {
name: 'Ed Spencer',
preferences: {
documentInstructions: `If I don't mention a specific project, I'm talking about Brag Doc.`,
language: 'en',
hasSeenWelcome: true
},
id: uuidv4(),
email: 'Q3Sd2@example.com',
} as User;
export const previousCompany = {
name: 'Palo Alto Networks',
id: uuidv4(),
startDate: new Date('2016-02-01'),
endDate: new Date('2021-09-30'),
userId: user.id,
role: 'Principal Engineer',
domain: 'www.paloaltonetworks.com',
};
export const company = {
name: 'Egghead Research',
id: uuidv4(),
startDate: new Date('2023-01-01'),
endDate: null,
userId: user.id,
role: 'Chief Scientist',
domain: 'www.edspencer.net',
};
export const project1 = {
name: 'BragDoc.ai',
description: 'AI-powered self-advocacy tool for tech-savvy individuals.',
startDate: new Date('2024-12-15'),
endDate: null,
id: uuidv4(),
companyId: company.id,
status: 'active',
userId: user.id,
repoRemoteUrl: null
}
export const project2 = {
name: 'mdx-prompt',
description: 'Composable LLM prompts with JSX and MDX',
I'm using Braintrust to run and track the Evals for bragdoc.ai, but most of this article really applies to any way of running them. You don't need to be using Braintrust specifically.
One thing they do formalize, though, is the idea of an Experiment. An Experiment is just a type that represents some input and some expected output. And here's where our careful thinking and structuring of our fetch/render/execute architecture pays off - we can just use our ExtractAchievementsPromptProps and ExtractedAchievement types to define our Experiment type:
extract-achievements.eval.ts
export type Experiment = {
input: ExtractAchievementsPromptProps;
expected: ExtractedAchievement[];
};
extract-achievements.eval.ts
export type Experiment = {
input: ExtractAchievementsPromptProps;
expected: ExtractedAchievement[];
};
This makes total sense. We're skipping the fetch stage as we're providing our own fake/controlled data set, so we're testing from ExtractAchievementsPromptProps to ExtractedAchievement[] on our diagram above.
Writing the Eval
Braintrust will help us run an array of these Experiments - here's how we structure this particular experiment, which is just a single chat message from the user:
extract-achievements.eval.ts
const chatHistory = [
{
role: 'user' as const,
content: 'I fixed several UX bugs in the checkout flow on Bragdoc today',
id: '1',
},
];
const lastMidnight = new Date();
lastMidnight.setHours(0, 0, 0, 0);
const nextMidnight = new Date();
nextMidnight.setDate(nextMidnight.getDate() + 1);
nextMidnight.setHours(0, 0, 0, 0);
const experimentData: Experiment[] = [
{
input: {
companies,
projects,
chatHistory,
user,
message: 'I fixed several UX bugs in the checkout flow on Bragdoc today',
},
expected: [
{
summary: 'Fixed several UX bugs in the checkout flow',
details: 'Fixed several UX bugs in the checkout flow on Bragdoc',
eventStart: lastMidnight,
eventEnd: nextMidnight,
impactSource: 'llm',
impactUpdatedAt: new Date(),
companyId: companies[0].id,
projectId: projects[0].id,
title: 'Fixed several UX bugs in the checkout flow',
eventDuration: 'day',
impact: 1,
},
],
},
];
extract-achievements.eval.ts
const chatHistory = [
{
role: 'user' as const,
content: 'I fixed several UX bugs in the checkout flow on Bragdoc today',
id: '1',
},
];
const lastMidnight = new Date();
lastMidnight.setHours(0, 0, 0, 0);
const nextMidnight = new Date();
nextMidnight.setDate(nextMidnight.getDate() + 1);
nextMidnight.setHours(0, 0, 0, 0);
const experimentData: Experiment[] = [
{
input: {
companies,
projects,
chatHistory,
user,
message: 'I fixed several UX bugs in the checkout flow on Bragdoc today',
},
expected: [
{
summary: 'Fixed several UX bugs in the checkout flow',
details: 'Fixed several UX bugs in the checkout flow on Bragdoc',
eventStart: lastMidnight,
eventEnd: nextMidnight,
impactSource: 'llm',
impactUpdatedAt: new Date(),
companyId: companies[0].id,
projectId: projects[0].id,
title: 'Fixed several UX bugs in the checkout flow',
eventDuration: 'day',
impact: 1,
},
],
},
];
We can see that the input is an instance of our ExtractAchievementsPromptProps type, and the expected is an array of ExtractedAchievement objects that we expect to be yielded by our execute() function. There is a third concept - output - which is the actual array of ExtractedAchievement objects that we get back from the LLM.
So in the end this eval is just testing that when the user sends a message in an otherwise empty chat session, saying "I fixed several UX bugs in the checkout flow on Bragdoc today", we get back the output of ExtractedAchievement objects that looks like what we expected, given the company/project/user data that we also fed the prompt with the rest of the input.
Fuzzy matching and LLMs as judges
Ok so we've got a good handle on what we're testing, and we've got some good test data to test it with. But how do we actually compare the ExtractedAchievement objects that we get back from the LLM with the ExtractedAchievement objects that we expect?
This bit is where it can be challenging, because there are arguably many different reasonable ways an LLM could respond to a given message like this. In other Experiments along the same lines, we want to be able to pass in very long messages and have a bunch of Achievements extracted from them. Some of the other Evals for bragdoc.ai do just that - setting up scenarios where we expect a dozen or more Achievements to be extracted from a single LLM invocation.
In this case we're essentially comparing 2 arrays of identically-shaped JSON objects, but there's still enough fuzziness in the LLM output that we can't just do a deep comparison of the arrays. We certainly can't expect to be able to run a full comparison of the 2 arrays because there is a lot of non-determinism in the LLM output.
So we need to be a bit more creative. We can use the LLM as a judge, and ask it to compare the output and expected arrays for us. We can do this by asking another LLM to compare each ExtractedAchievement object in the output array with each ExtractedAchievement object in the expected array, and give us a score for how similar they are.
This general technique is called "LLM as a Judge", and it's a powerful way to compare fuzzy data. We can use it to compare the output and expected arrays, and then use that comparison to decide whether the Eval passed or failed. Conveniently, we can use mdx-prompt to write the prompt that does this comparison for us:
extract-achievement-scorer.tsx
//snipped for brevity, contains instructions on how to compare the output and expected arrays
const instructions = ['...']
//tell the LLM how to score the comparison
const outputFormat = `
Answer by selecting one of the following options:
(A) The extraction matches the expected output perfectly
(B) The extraction captures the main achievement but misses some details
(C) The extraction has minor inaccuracies but is generally correct
(D) The extraction misses key information or has significant inaccuracies
(E) The extraction is completely incorrect or misunderstands the achievement`;
function EvaluateExtractedAchievementsPrompt({
expectedAchievements,
extractedAchievements,
}: {
expectedAchievements: any;
extractedAchievements: any;
}) {
return (
<Prompt>
<Purpose>
You are evaluating how well an AI system extracted achievements from a
user message. Compare the extracted achievements with the expected
output. Consider that a single message may contain multiple
achievements. Return one of the scores defined below.
</Purpose>
<Instructions instructions={instructions} />
<InputFormat>
<expected-achievements>
The correct Achievements that should have been extracted by the model
</expected-achievements>
<extracted-achievements>
The achievements that were actually extracted by the model
That's a fairly simple prompt that just tells the LLM what data it's going to get, how to evaluate it, and then gives it the data. The LLM will then return a score that will give us some indication of how well the output and expected arrays match.
In order to do that within the Braintrust way of doing things, we can define a scorer:
extract-achievement-scorer.tsx
export async function ExtractAchievementScorer(args: any): Promise<Score> {
And now we can tie it all together to run all of our Experiments (all one of them, in this case) and use our ExtractAchievementScorer to score the comparison of the output and expected arrays:
extract-achievements.eval.ts
Eval('extract-chat-achievements', {
data: experimentData,
task: wrappedExtractAchievements,
scores: [ExtractAchievementScorer],
trialCount: 3,
metadata: {
model: 'gpt-4',
description: 'Evaluating achievement extraction',
owner: 'ed',
},
});
// Function to wrap the async generator into a promise that resolves to an array of ExtractedAchievements
async function wrappedExtractAchievements(input: ExtractAchievementsPromptProps): Promise<ExtractedAchievement[]> {
return await renderExecute(input);
}
extract-achievements.eval.ts
Eval('extract-chat-achievements', {
data: experimentData,
task: wrappedExtractAchievements,
scores: [ExtractAchievementScorer],
trialCount: 3,
metadata: {
model: 'gpt-4',
description: 'Evaluating achievement extraction',
owner: 'ed',
},
});
// Function to wrap the async generator into a promise that resolves to an array of ExtractedAchievements
async function wrappedExtractAchievements(input: ExtractAchievementsPromptProps): Promise<ExtractedAchievement[]> {
return await renderExecute(input);
}
The task function is just what Braintrust runs for each Experiment to produce the output - here finally is where we use that renderExecute function from extract-achievements.ts to pass in our test data and get back a Promise that resolves to an array of ExpectedAchievement objects. The experimentData is the array of Experiment instances we defined earlier in this article.
Experiment mdx-prompt-polish-1737670065 is running at https://www.braintrust.dev/app/Egghead/p/extract-chat-achievements/experiments/mdx-prompt-polish-1737670065
See results for mdx-prompt-polish-1737670065 at https://www.braintrust.dev/app/Egghead/p/extract-chat-achievements/experiments/mdx-prompt-polish-1737670065
Experiment mdx-prompt-polish-1737670065 is running at https://www.braintrust.dev/app/Egghead/p/extract-chat-achievements/experiments/mdx-prompt-polish-1737670065
See results for mdx-prompt-polish-1737670065 at https://www.braintrust.dev/app/Egghead/p/extract-chat-achievements/experiments/mdx-prompt-polish-1737670065
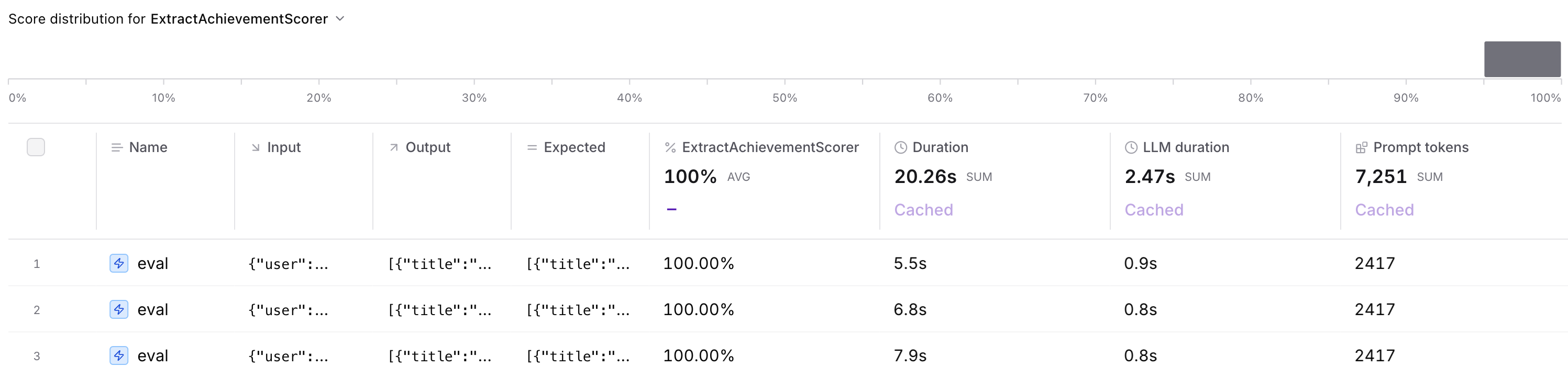
In this case we can see that our LLM as a judge generously awarded us a 100% score for our extraction of Achievements from source messages, when it compares them to the expected Achievements:
Braintrust gives us some stats on our eval, and can track it over time
Conclusions
This was just implementing a single Eval to test a single LLM feature under a single scenario. For all that work we now have an automated way of quantifying how well our LLM prompt is working for this feature. The fact that we can now run these Evals at development time and in CI means that we can have confidence that we haven't unknowingly broken something as we meddle with the prompt or other code some time in the future.
Pictures are useful, Types are too
I made that pretty flow chart diagram before I ended up with the code in its final form. Once I had drawn that out, the render/execute/fetch cycle kinda leapt off the page and asserted itself as a fairly generalized architecture for invoking these types of prompts.
I found this pattern cropping up again and again, and in reality there are several ways that we want to compose those individual functions. Sometimes we want an async generator so we can stream things to the user, other times a Promise is better, other times we already have the data and just want to pass it in and get the result back, and so on.
Having a clear model for how your prompts work is critical to structuring evals that make sense.
Good test data is useful
One bonus benefit of having good Evals is that if you have good Evals you by definition have good test data, at least when it comes to rendering prompts covered by your evals. I made a page at https://www.bragdoc.ai/prompt that uses Next JS to render prompts in the browser. You can open that page (no account needed to access this page) and see exactly what the rendered prompts used by bragdoc.ai look like:
That's just a fairly simple Next JS page.tsx that uses a basic component called PrettyPrompt to render three different prompts. It's currently hooked up to use that eval data, which is why you can go look at it without being logged in, but you can see how easy it would be to hook it up to real data to debug how your prompts actually get rendered.
Evals are slow, expensive and difficult
Your unit test suite should ideally run in about a second, triggered automatically each time you save a file in your IDE. Evals are never going to do that - they're far too slow, and sometimes the output is itself in shades of gray that just don't exist in the world of unit tests. So Evals are their own separate thing, run much less often. But still before every merge to main.
While developing bragdoc.ai, which is a fairly typical AI SaaS app, I found that whereas I could rely on Windsurf and other AI tooling for building out most of the app itself, building Evals was not something the AI excelled at. Or at least, my attempts to use AI to build evals were not very successful. After a few weeks of flying through implementation when it comes to adding features, I spent the last week just basically getting Evals under control.
They're a lot of work, and famously difficult to get right. Bragdoc only has a handful of them so far, but I see the value in them and will continue to add them. They also unlock some really significant benefits when it comes to assessing which LLM works best for which prompt, whether it be in terms of accuracy, cost or latency. But that's a topic for another day.