AI Content Recommendations with TypeScript
Easy RAG for TypeScript and React Apps Part 2 - Generating content recommendations using ReadNext
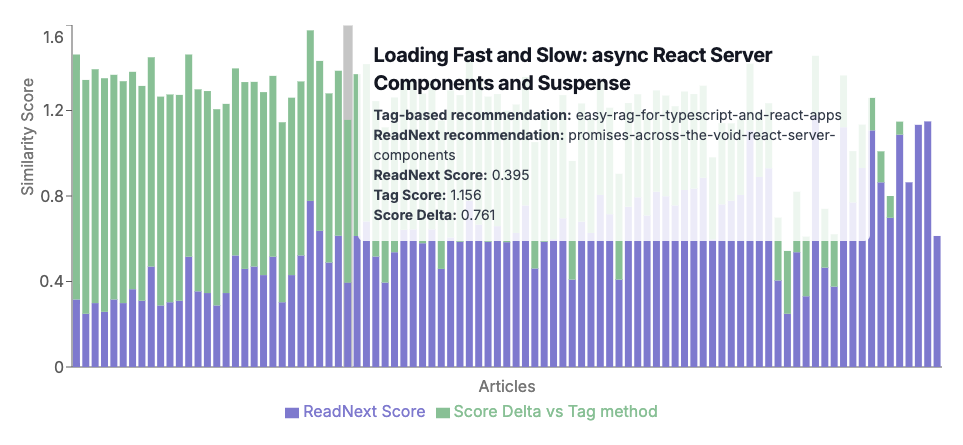
Recently I posted about AI Content Recommendations with TypeScript, which concluded by introducing a new NPM package I've been working on called ReadNext. This post is dedicated to ReadNext, and will go into more detail about how to use ReadNext in Node JS, React, and other JavaScript projects.
ReadNext is a Node JS package that uses AI to generate content recommendations. It's designed to be easy to use, and can be integrated into any Node JS project with just a few lines of code. It is built on top of LangChain, and delegates to an LLM of your choice for summarizing your content to generate recommendations. It runs locally, does not require you to deploy anything, and has broad support for a variety of content types and LLM providers.
ReadNext is not an AI itself, nor does it want your money, your data or your soul. It's just a library that makes it easy to find related content for developers who use JavaScript as their daily driver. It's best used at build time, and can be integrated into your CI/CD pipeline to generate recommendations for your content as part of your build process.
Get started in the normal way:
Configure a ReadNext instance:
Index your content:
Generate recommendations:
That's it! Under the covers, ReadNext creates embeddings for your content - after first running it through a summarization process - then stores the embeddings in a FAISS vector store. This allows it to keep a local cache of the work it has done, and to quickly generate recommendations for your content.

I use ReadNext on this blog to generate related content recommendations for each post. It's a Next JS app, so I run ReadNext as part of the build process to generate recommendations for each post. The recommendations are stored in the frontmatter of each post (I use .mdx files for the blog content), and displayed at the bottom of each post.
It's also being used inside my RSC Examples project, which is an open source collection of examples of how to use React Server Components in various contexts. Each example has some explanatory text and code snippets, along with a live example, but even though that's not a traditional "article" per se, ReadNext is flexible enough to work with it.
Here's the actual script that RSC Examples uses to generate related examples for each example:
The script just does 3 simple things:
The RSC Examples project stores its content as .mdx files, so the final part of the script is just calling a utility function to update the frontmatter on each example with the related examples that ReadNext generated.
The summarizationPrompt is optional but here we're taking advantage of it to better explain to the LLM that the content it is about to transform is a markdown document about an example of how to use React Server Components, not a long form article as it would usually expect. Here's the full thing:
Here's the actual commit that was everything required to get ReadNext completely integrated with RSC Examples (the next commit shows the output that ReadNext generated). There are a couple of simple UI components to display the recommendations, otherwise it's just one script that runs ReadNext to (re-)generate the recommendations.
I spend most of my time in React, usually within Next JS, and typically write TypeScript, so most of what I create is a union of those technologies. ReadNext is really a node project, and you don't need anything to do with React/Next/TypeScript to use it. But it does work really well with those technologies, because that's my stack and it would annoy me if it didn't.
The first time ReadNext runs, it needs to index all of the content you give it. Because this involves a summarization step, this can take a few seconds per article. Subsequent runs will be faster because ReadNext caches the summarizations and only regenerates them if it detects that an article's content has changed.
Every time a new article is added, or an existing article is updated, it's a good idea to re-run ReadNext as it's possible that your changes will alter the recommendations for one or more of your articles. Automating this as part of your build process is a good idea, and because ReadNext is a self-contained package it should be able to run pretty much anywhere.
To further expand your knowledge on integrating AI with JavaScript projects, consider reading AI Content Recommendations with TypeScript, which discusses leveraging AI for personalized content suggestions. Additionally, Introducing InformAI - Easy & Useful AI for React apps offers a practical overview of connecting React components with AI models, streamlining the AI integration process in web applications.
Easy RAG for TypeScript and React Apps Part 2 - Generating content recommendations using ReadNext

RAG is not just for Pythonistas - it's easy and powerful with TypeScript and React too
InformAI lets AI see what your user sees in your React apps
Markdown is a really nice way to write content like blog posts and other long-form content, with live components inside
herdctl runs Claude Code agents securely in Docker, with schedules and chat
Learn morePerformance review optimization for software professionals
Try BragDoc freeherdctl runs Claude Code agents securely in docker, with optional schedules and chat
→ Read moremdx-prompt lets you write reusable and composable LLM prompts using JSX
→ Read morebragdoc.ai is an open source Next JS AI SaaS app for tracking your work
→ Read morereact-auto-intl automatically internationalizes and translates React and Next JS apps
→ Read moreNarratorAI creates AI-powered content like intros and search result summaries
→ Read moreInformAI allows AI to access and understand the information in your React components
→ Read moreReadNext creates AI-powered content recommendations for your blog or other content
→ Read moreI've built things on the web for 20 years, and used JavaScript before it was cool.
I've been working for myself since early 2023, going wherever my heart takes me - mostly playing with AI and UI.