AI Content Recommendations with TypeScript
Easy RAG for TypeScript and React Apps Part 2 - Generating content recommendations using ReadNext
This is the first article in a trilogy that will go through the process of extracting content from a large text dataset - my blog in this case - and making it available to an LLM so that users can get answers to their questions without searching through lots of articles along the way.
Part 1 will cover how to process your text documents for easy consumption by an LLM, throw those embeddings into a vector database, and then use that to help answer the user's questions. There are a million articles about this using Python, but I'm principally a TypeScript developer so we'll focus on TS, React and NextJS.
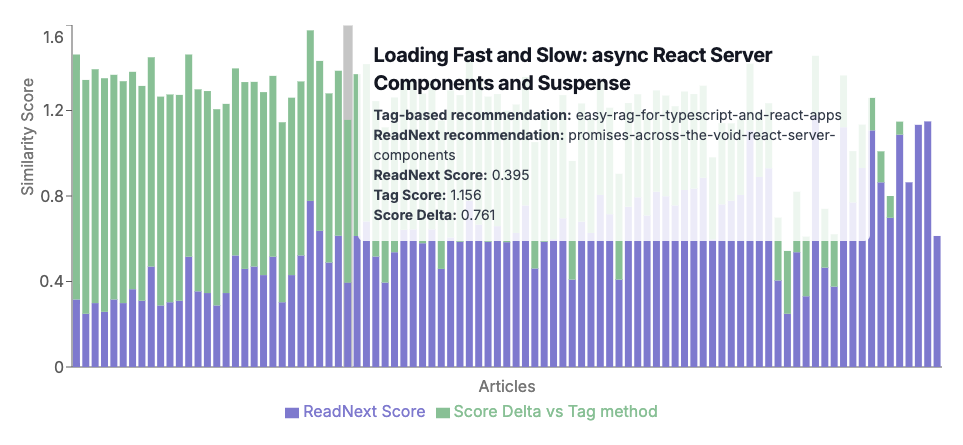
Part 2 covers how to make an AI-driven "What to Read Next" component, which looks at the content of an document (or blog post, in this case) and performs a semantic search through the rest of the content to rank which other posts are most related to this one, and suggest them.
Part 3 will extend this idea by using InformAI to track which articles the user has looked at and attempt to predictively generate suggested content for that user, personalizing the What to Read Next component while keeping the reader completely anonymous to the system.
About a week ago I released InformAI, which allows you to easily surface the state of your application UI to an LLM in order to help it give more relevant responses to your user. In that intro post I threw InformAI into the blog post itself, which gave me a sort of zero-effort poor man's RAG, as the LLM could see the entire post and allow people to ask questions about it.
That's not really what InformAI is intended for, but it's nice that it works. But what if we want to do this in a more scalable and coherent way? This blog has around 100 articles, often about similar topics. Sometimes, such as when I release open source projects like InformAI, it's one of the only sources of information on the internet about the given topic. You can't ask ChatGPT what InformAI is, but with a couple of tricks we can transparently give ChatGPT access to the answer so that it seems like it magically knows stuff it was never trained on.
In reality, having a chatbot that is able to answer questions about content from my blog is not likely to be super useful, but the process to achieve it is adaptable to many situations. It's likely that your company has hundreds or thousands of internal documents that contain answers to all kinds of questions, but finding that information can be difficult, and you may need to manually piece information together from a bunch of sources to get to the answer you need.
Retrieval Augmented Generation refers to a group of techniques to intercept a user's message on its way to an LLM, look at what the user wrote, try to find relevant information from your own dataset about that question, and then pass that information along with the original question to the LLM, with the hope that the LLM will use it to give the user a good answer.
Concretely, what this usually boils down to is jamming a bunch of additional text content into the LLM prompt, usually labelling that as "Context", then passing the user query afterwards:
Ok so how do we actually achieve that? How do we pluck the relevant sections from a large corpus of text? Clearly, this requires 3 things:
So how do we compute a semantic similarity score between two text strings? Well, first we turn the text into an array of numbers, called an embedding. This array is often referred to as a vector, because it is one, but it's also just an array of (usually floating point) numbers.
The "magic" of embedding creation is the process of turning a text string into that vector. I won't go into how that actually happens here, but for now it's enough to know that other people have done the hard work of making that possible, and that once we've produced embeddings for 2 strings, it's very easy to compare those two vectors and see how similar the strings are. This is the crux of what powers RAG - figuring out how similar strings are.
So how do we create this vector for a given string? We don't; we get an embedding model to do it for us. Most of the major LLM providers have an embedding API you can call with a text string and get a vector back. Here's how we do it with OpenAI, for example:
Ok, that was pretty easy. In fact, we already achieved our first objective from above (Understanding what a question is about). Let's move on to the second objective - understanding what the text in the source documents is about.
We've got an easy way to turn strings of text into embedding vectors by calling an API, so we can just grab our source documents and do this for each of them, right? Well, kinda. It turns out that most embedding models have a strict limit on the length of a text string that you can pass in. In the case of the text-embedding-ada-002 embedding model that we're using here, that limit is 8192 tokens.
Most of the articles here flirt with that limit, with maybe half of them being a little longer than the embedding model can handle. How do we handle this? By splitting the source documents up, of course. There are a bunch of ways you could split a text document, with pros and cons to each. If you want to get serious about it, using a library like LangChain is probably the way to go, as it has a bunch of strategies for sensibly chunking text documents.
But I didn't want to add a dependency to my app just to chunk text, so I just wrote a little function to chunk my text files instead. As I mentioned in the last post, my blog uses MDX to blend Markdown and React components for its content, so one decent strategy here is to just split the .mdx file (after removing the frontmatter of course) by heading:
Technically, this function doesn't guarantee that our chunks are under the 8192 token limit, but in practice the chunks it generates are all substantially smaller than that limit. Again, for more robustness it's better to use something like LangChain for this.
Now that we've got our chunks, though, it's easy to generate embeddings for our entire text corpus:
Cool - now we've solved objectives 1 & 2 - we've got vector embeddings for our entire text corpus, as well as an easy way to vectorize questions from the user. But right now it's all just a bunch of arrays in memory - what we need is a way to compare our user question vector with all the embeddings we made for our text content. We need a vector database.
Vector Databases come in many forms. You can, of course, stuff vectors into pretty much any database - they're just arrays of numbers after all, but what we mean by "Vector Database" is one that makes it easy to pluck out vectors that are similar to one provided as our query (our vectorized/embedded user question, for example).
A bunch of vector-optimized databases have cropped up recently, but even traditional relational databases like Postgres and mysql are gaining vector capabilities, which may make things easier if you've already got one of those in your mix. In my case, there was no existing database behind this blog, so I decided to integrate with a relatively new player in the market - Astra by DataStax.
Astra is attractive for my use case because it's cloud hosted, allowing me to continue deploying my largely SSG blog application to Vercel without having to worry about orchestrating database deployments, migrations, or anything like that. It's far from the only option, but it's the one I took in this case. It's also free at my usage level, which is also cool.
DataStax provides a simple npm package called @datastax/astra-db-ts that makes it pretty easy to interact with Astra. Under the covers Astra is built on top of Cassandra, so it may be familiar already. I made a tiny astra.ts that exports a couple of functions like getCollection to make it easier for my embedding.ts file to interact with it:
The only slight hitch I ran into was creating a token with the appropriate access - they have an RBAC system for tokens (which is good), but I had to create a token with more access than I expected to make it actually work (which is not so good). Anyway, to actually upload the embeddings we made before, we can just call collection.insertMany:
That's it really. I skipped the bit about creating an account, database and collection within Astra, but I'm sure you can figure that out from their docs. Now all we have to do is grab our user message and fetch semantically similar text content from Astra.
And here's how we can do that. This function just takes our user's question, turns it into an embedding, then searches our Astra database collection for similar embeddings using a vector search. Assuming we got some searchResults back, it will then just plop those into a prompt string along with the user's query, then send that along to OpenAI:
The response that we get back from the LLM should benefit from the context we found via semantic search, unless our results were not very good. Our searchResults array does include a similarity score for each result, so we can perform a cutoff or other processing to make sure we're only passing genuinely relevant content to the LLM. We can, of course, also modify the prompt itself to say things like "Using only the content provided here, please answer the user's question", or other text to try to constrain the LLM's response and limit its tendency to hallucinate. YMMV.
Finally, that example above just used the basic OpenAI chat completion API, which will potentially sit there for a long time before showing you the entire LLM response in one go. That's a poor UX, so it's usually better to stream that text back. I'm a big fan of the Vercel AI SDK, and recently wrote about how to use that alongside the basic ChatWrapper React component in InformAI to get a quick and dirty chatbox interface up and running.
None of this needs InformAI at all - I just happen to be using it already so I stuck with that, but you could equally roll your own chatbot UI, use useChat from Vercel or find something else from off the shelf. Here's a live chatbot that you can ask any question about any article on this site (see the InformAI README for how to use this UI component):
Here's the actual code that I'm using on the back end to make this work. Most of this is taken directly from the InformAI README - I just added the for..of loop to replace your message to the LLM with the one returned from prepareRAGMessage:
And that's it - we've got LLM responses streaming into our React frontend that allow users to ask questions about things that ChatGPT was never trained on, but can give reasonable answers to anyway because we have RAG. In the next part we'll look at how to extend our use of RAG to generate more meaningful "Read Next" suggestions for our articles, before moving on to making intelligent, personalized suggestions based on reading history.
For the next step in enhancing your TypeScript and React projects with AI, read AI Content Recommendations with TypeScript, which delves into creating personalized "What to Read Next" components. Additionally, ReadNext: AI Content Recommendations for Node JS can provide a broader understanding of leveraging AI for content suggestions in JavaScript projects.
Easy RAG for TypeScript and React Apps Part 2 - Generating content recommendations using ReadNext
ReadNext is a new npm package that creates content recommendations for your Node JS projects.
InformAI lets AI see what your user sees in your React apps
Markdown is a really nice way to write content like blog posts and other long-form content, with live components inside
herdctl runs Claude Code agents securely in Docker, with schedules and chat
Learn moreTrack achievements automatically - boost your performance reviews
Try demo modeherdctl runs Claude Code agents securely in docker, with optional schedules and chat
→ Read moremdx-prompt lets you write reusable and composable LLM prompts using JSX
→ Read morebragdoc.ai is an open source Next JS AI SaaS app for tracking your work
→ Read morereact-auto-intl automatically internationalizes and translates React and Next JS apps
→ Read moreNarratorAI creates AI-powered content like intros and search result summaries
→ Read moreInformAI allows AI to access and understand the information in your React components
→ Read moreReadNext creates AI-powered content recommendations for your blog or other content
→ Read moreI've built things on the web for 20 years, and used JavaScript before it was cool.
I've been working for myself since early 2023, going wherever my heart takes me - mostly playing with AI and UI.